セット前のテストは違いを生みますが、その程度はユースケースによって異なります。
どちらの場合でも、データは最終的にキャッシュ ラインになります (たとえば、書き込みのみまたはテスト アンド セット)。
ただし、キャッシュ ラインがダーティ (変更など) としてタグ付けされているか、クリーンとしてタグ付けされている場合は違いがあります。汚れたキャッシュ ラインはメイン メモリに書き戻す必要がありますが、クリーンなキャッシュ ラインは単に忘れられ、新しいデータで満たされる可能性があります。
ここで、コードが大量のデータを破壊し、データの各チャンクに 1 回か 2 回しかアクセスしないとします。その場合、メモリ アクセスのほとんどがキャッシュ ミスであると想定できます。キャッシュ ミスが発生した時点でキャッシュ ラインの大部分がダーティであり、キャッシュ ラインの大部分がダーティである場合はどうなりますか?
新しいデータをラインにロードする前に、それらをメイン メモリに書き戻す必要があります。これは、キャッシュラインの内容を単に忘れるよりも遅くなります。また、キャッシュとメイン メモリ間のメモリ帯域幅が 2 倍になります。
最近のメモリは高速であるため、1 つの CPU コアでは違いがないかもしれませんが、別の CPU が (うまくいけば) 他の作業も行います。バスがキャッシュラインの出し入れで忙しくない場合は、他の CPU コアがすべてを少し速く実行することを確認できます。
要するに、キャッシュラインをきれいに保つことで、必要な帯域幅が半分になり、キャッシュミスが少し安くなります。
ブランチについて:確かに:コストはかかりますが、キャッシュ ミスはさらに悪いことです!また、運が良ければ、CPU はアウト オブ オーダー実行機能を使用して、ブランチのコストでキャッシュ ミスを相殺します。
このコードから可能な限り最高のパフォーマンスを得たい場合、およびほとんどのアクセスがキャッシュ ミスである場合は、次の 2 つのオプションがあります。
- <リ>
キャッシュをバイパスする:x86 アーキテクチャには、この目的のための非一時的なロードとストアがあります。これらは SSE 命令セットのどこかに隠され、組み込み関数を介して C 言語から使用できます。
<リ>(上級者向け):テスト アンド セット関数を CMOV (条件付き移動) 命令を使用するアセンブラに置き換えるインライン アセンブラの一部の行を使用します。これにより、キャッシュラインがきれいに保たれるだけでなく、分岐が回避されます。現在、CMOV は低速の命令であり、分岐が予測できない場合にのみ分岐よりも優れています。したがって、コードのベンチマークをより適切に行うことができます。
これは興味深い質問であり、キャッシュ ラインに関する Nils の回答は間違いなく優れたアドバイスです。
実際のパフォーマンスを測定するためのコードのプロファイリングの重要性を強調したいと思います -- 遭遇したデータでそのフラグがすでに設定されている頻度を測定できますか?答え次第でパフォーマンスが大きく変わる可能性があります。
楽しみのために、あなたのコードを使用して、さまざまな比率の 1 で満たされた 5000 万要素の配列で、set と test-then-set の比較を少し実行しました。グラフは次のとおりです:
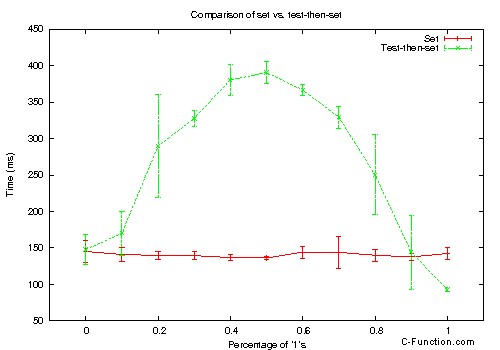
(ソース:natekohl.net)
もちろん、これは単なるおもちゃの例です。しかし、私が期待していなかった非線形のパフォーマンスに注意してください。また、配列がほぼ完全に 1 で満たされている場合、テスト後セットは通常のセットよりも高速になります。
これらはあなたの要求に対する私の解釈です。
- フラグを個別に初期化しています
- 一度だけ (1 に) セットされ、その後はリセットされません
- しかし、このセットの試みは同じ旗で何度も行われます
- そして、これらのフラグ インスタンスがたくさんあります (それぞれに同じ種類の処理が必要です)
と仮定すると、
- スペースの最適化は、時間の最適化よりもかなり低い重み付けされています。
次のことを提案します。
- まず、32 ビット システムでアクセス時間が心配な場合は、32 ビット整数を使用すると便利です
- フラグ 'word' のチェックをスキップすると、書き込みは非常に高速になります。ただし、まだ設定されていない場合はチェックして設定する非常に多くのフラグがある場合は、条件付きチェックを維持することをお勧めします。
- ただし、プラットフォームが並列操作を行う場合 (たとえば、通常、コードの実行と並行してディスクへの書き込みを送信できる場合) は、チェックをスキップする価値があります。