このプログラムは、このリンク (https://gist.github.com/jiewmeng/3787223) から取得しました。プロセッサ キャッシュ (L1 および L2) について理解を深めたいと考えて Web を検索しています。新しいラップトップの L1 および L2 キャッシュのサイズを推測できるプログラムを作成することができました (学習目的のためです。仕様を確認できることはわかっています)。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define KB 1024
#define MB 1024 * 1024
int main() {
unsigned int steps = 256 * 1024 * 1024;
static int arr[4 * 1024 * 1024];
int lengthMod;
unsigned int i;
double timeTaken;
clock_t start;
int sizes[] = {
1 * KB, 4 * KB, 8 * KB, 16 * KB, 32 * KB, 64 * KB, 128 * KB, 256 * KB,
512 * KB, 1 * MB, 1.5 * MB, 2 * MB, 2.5 * MB, 3 * MB, 3.5 * MB, 4 * MB
};
int results[sizeof(sizes)/sizeof(int)];
int s;
/*for each size to test for ... */
for (s = 0; s < sizeof(sizes)/sizeof(int); s++)
{
lengthMod = sizes[s] - 1;
start = clock();
for (i = 0; i < steps; i++)
{
arr[(i * 16) & lengthMod] *= 10;
arr[(i * 16) & lengthMod] /= 10;
}
timeTaken = (double)(clock() - start)/CLOCKS_PER_SEC;
printf("%d, %.8f \n", sizes[s] / 1024, timeTaken);
}
return 0;
}
私のマシンでのプログラムの出力は次のとおりです。数値をどのように解釈すればよいですか?このプログラムは何を教えてくれますか?
1, 1.07000000
4, 1.04000000
8, 1.06000000
16, 1.13000000
32, 1.14000000
64, 1.17000000
128, 1.20000000
256, 1.21000000
512, 1.19000000
1024, 1.23000000
1536, 1.23000000
2048, 1.46000000
2560, 1.21000000
3072, 1.45000000
3584, 1.47000000
4096, 1.94000000
答え:
-
メモリに直接アクセスする必要がある
DMA という意味ではありません これで転送。 CPU がメモリにアクセスする必要があります もちろん (それ以外の場合は CACHE を測定していません) s) しかし、可能な限り直接的に...そのため、Windows/Linux では測定値はおそらくあまり正確ではありません サービスやその他のプロセスが実行時にキャッシュを混乱させる可能性があるためです。より良い結果を得るには、何度も測定して平均します (または、最速の時間を使用するか、一緒にフィルター処理します)。最高の精度を得るには、DOS を使用してください と asm 例えば
rep + movsb,movsw,movsd
rep + stosb,stosw,stosd
したがって、コード内のようなものではなく、メモリ転送を測定します!!!
-
生の転送時間を測定し、グラフをプロット
x軸は転送ブロック サイズですy軸は転送速度です
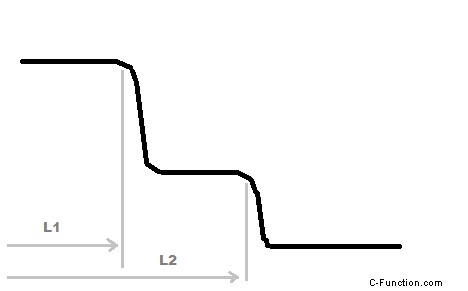
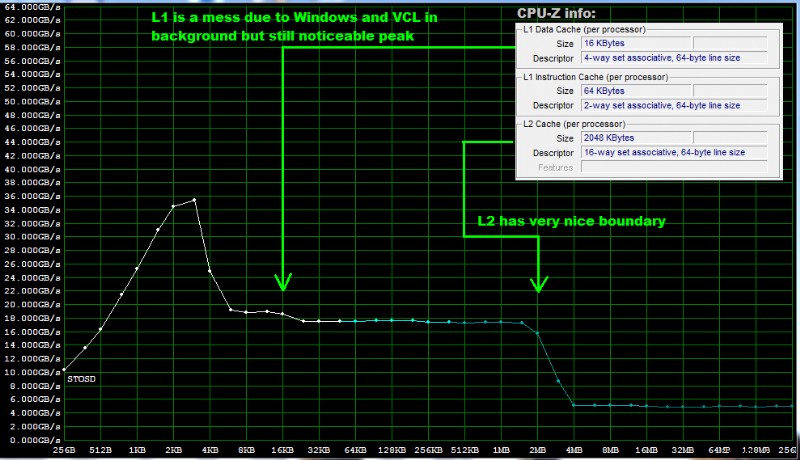
同じ転送レートのゾーンは、適切な CACHE と一致しています レイヤー
[編集 1] このための古いソース コードを見つけることができなかったので、C++ で今何かを壊しました 窓用 :
時間計測:
//---------------------------------------------------------------------------
double performance_Tms=-1.0, // perioda citaca [ms]
performance_tms= 0.0; // zmerany cas [ms]
//---------------------------------------------------------------------------
void tbeg()
{
LARGE_INTEGER i;
if (performance_Tms<=0.0) { QueryPerformanceFrequency(&i); performance_Tms=1000.0/double(i.QuadPart); }
QueryPerformanceCounter(&i); performance_tms=double(i.QuadPart);
}
//---------------------------------------------------------------------------
double tend()
{
LARGE_INTEGER i;
QueryPerformanceCounter(&i); performance_tms=double(i.QuadPart)-performance_tms; performance_tms*=performance_Tms;
return performance_tms;
}
//---------------------------------------------------------------------------
ベンチマーク (32 ビット アプリ):
//---------------------------------------------------------------------------
DWORD sizes[]= // used transfer block sizes
{
1<<10, 2<<10, 3<<10, 4<<10, 5<<10, 6<<10, 7<<10, 8<<10, 9<<10,
10<<10, 11<<10, 12<<10, 13<<10, 14<<10, 15<<10, 16<<10, 17<<10, 18<<10,
19<<10, 20<<10, 21<<10, 22<<10, 23<<10, 24<<10, 25<<10, 26<<10, 27<<10,
28<<10, 29<<10, 30<<10, 31<<10, 32<<10, 48<<10, 64<<10, 80<<10, 96<<10,
112<<10,128<<10,192<<10,256<<10,320<<10,384<<10,448<<10,512<<10, 1<<20,
2<<20, 3<<20, 4<<20, 5<<20, 6<<20, 7<<20, 8<<20, 9<<20, 10<<20,
11<<20, 12<<20, 13<<20, 14<<20, 15<<20, 16<<20, 17<<20, 18<<20, 19<<20,
20<<20, 21<<20, 22<<20, 23<<20, 24<<20, 25<<20, 26<<20, 27<<20, 28<<20,
29<<20, 30<<20, 31<<20, 32<<20,
};
const int N=sizeof(sizes)>>2; // number of used sizes
double pmovsd[N]; // measured transfer rate rep MOVSD [MB/sec]
double pstosd[N]; // measured transfer rate rep STOSD [MB/sec]
//---------------------------------------------------------------------------
void measure()
{
int i;
BYTE *dat; // pointer to used memory
DWORD adr,siz,num; // local variables for asm
double t,t0;
HANDLE hnd; // process handle
// enable priority change (huge difference)
#define measure_priority
// enable critical sections (no difference)
// #define measure_lock
for (i=0;i<N;i++) pmovsd[i]=0.0;
for (i=0;i<N;i++) pstosd[i]=0.0;
dat=new BYTE[sizes[N-1]+4]; // last DWORD +4 Bytes (should be 3 but i like 4 more)
if (dat==NULL) return;
#ifdef measure_priority
hnd=GetCurrentProcess(); if (hnd!=NULL) { SetPriorityClass(hnd,REALTIME_PRIORITY_CLASS); CloseHandle(hnd); }
Sleep(200); // wait to change take effect
#endif
#ifdef measure_lock
CRITICAL_SECTION lock; // lock handle
InitializeCriticalSectionAndSpinCount(&lock,0x00000400);
EnterCriticalSection(&lock);
#endif
adr=(DWORD)(dat);
for (i=0;i<N;i++)
{
siz=sizes[i]; // siz = actual block size
num=(8<<20)/siz; // compute n (times to repeat the measurement)
if (num<4) num=4;
siz>>=2; // size / 4 because of 32bit transfer
// measure overhead
tbeg(); // start time meassurement
asm {
push esi
push edi
push ecx
push ebx
push eax
mov ebx,num
mov al,0
loop0: mov esi,adr
mov edi,adr
mov ecx,siz
// rep movsd // es,ds already set by C++
// rep stosd // es already set by C++
dec ebx
jnz loop0
pop eax
pop ebx
pop ecx
pop edi
pop esi
}
t0=tend(); // stop time meassurement
// measurement 1
tbeg(); // start time meassurement
asm {
push esi
push edi
push ecx
push ebx
push eax
mov ebx,num
mov al,0
loop1: mov esi,adr
mov edi,adr
mov ecx,siz
rep movsd // es,ds already set by C++
// rep stosd // es already set by C++
dec ebx
jnz loop1
pop eax
pop ebx
pop ecx
pop edi
pop esi
}
t=tend(); // stop time meassurement
t-=t0; if (t<1e-6) t=1e-6; // remove overhead and avoid division by zero
t=double(siz<<2)*double(num)/t; // Byte/ms
pmovsd[i]=t/(1.024*1024.0); // MByte/s
// measurement 2
tbeg(); // start time meassurement
asm {
push esi
push edi
push ecx
push ebx
push eax
mov ebx,num
mov al,0
loop2: mov esi,adr
mov edi,adr
mov ecx,siz
// rep movsd // es,ds already set by C++
rep stosd // es already set by C++
dec ebx
jnz loop2
pop eax
pop ebx
pop ecx
pop edi
pop esi
}
t=tend(); // stop time meassurement
t-=t0; if (t<1e-6) t=1e-6; // remove overhead and avoid division by zero
t=double(siz<<2)*double(num)/t; // Byte/ms
pstosd[i]=t/(1.024*1024.0); // MByte/s
}
#ifdef measure_lock
LeaveCriticalSection(&lock);
DeleteCriticalSection(&lock);
#endif
#ifdef measure_priority
hnd=GetCurrentProcess(); if (hnd!=NULL) { SetPriorityClass(hnd,NORMAL_PRIORITY_CLASS); CloseHandle(hnd); }
#endif
delete dat;
}
//---------------------------------------------------------------------------
配列 pmovsd[] と pstosd[] 測定された 32bit を保持します 転送レート [MByte/sec] .測定関数の開始時に use/rem 2 つの定義を使用してコードを構成できます。
グラフィック出力:

精度を最大化するために、プロセスの優先度クラスを変更できます 最大に。したがって、最大の優先度で測定スレッドを作成し (試してみましたが、実際にはうまくいきません)、クリティカル セクション を追加します。 OS によってテストが中断されないようにします。 頻繁に(スレッドの有無にかかわらず目に見える違いはありません)。 Byte を使用する場合 転送は 16bit のみを使用することを考慮に入れる を登録するので、ループとアドレスの反復を追加する必要があります。
追記
ノートパソコンでこれを試すと、CPU が過熱するはずです 上部の CPU/Mem を測定していることを確認してください 速度。だから Sleep 秒。測定前のいくつかのばかげたループはそれを行いますが、少なくとも数秒間実行する必要があります。また、これを CPU で同期することもできます 上昇中の周波数測定とループ。飽和したら停止 ...
アスム 命令 RDTSC が最適です (ただし、新しいアーキテクチャではその意味が少し変わっていることに注意してください)。
Windows を使用していない場合 次に関数 tbeg,tend を変更します OS に 同等物
[edit2] 精度のさらなる向上
VCL でようやく問題を解決した後 この質問のおかげで発見した測定精度に影響を与え、ここでそれについて詳しく説明します。ベンチマークの前にこれを行うことで精度を向上させることができます:
-
プロセス優先度クラスを
realtimeに設定 -
プロセス アフィニティを単一の CPU に設定
単一の CPU だけを測定します マルチコアで
-
データと命令のキャッシュをフラッシュ
例:
// before mem benchmark
DWORD process_affinity_mask=0;
DWORD system_affinity_mask =0;
HANDLE hnd=GetCurrentProcess();
if (hnd!=NULL)
{
// priority
SetPriorityClass(hnd,REALTIME_PRIORITY_CLASS);
// affinity
GetProcessAffinityMask(hnd,&process_affinity_mask,&system_affinity_mask);
process_affinity_mask=1;
SetProcessAffinityMask(hnd,process_affinity_mask);
GetProcessAffinityMask(hnd,&process_affinity_mask,&system_affinity_mask);
}
// flush CACHEs
for (DWORD i=0;i<sizes[N-1];i+=7)
{
dat[i]+=i;
dat[i]*=i;
dat[i]&=i;
}
// after mem benchmark
if (hnd!=NULL)
{
SetPriorityClass(hnd,NORMAL_PRIORITY_CLASS);
SetProcessAffinityMask(hnd,system_affinity_mask);
}
したがって、より正確な測定は次のようになります: