今日は、C++ に関する皆さんの誤解について、私の話を締めくくります。これらの神話は、関数パラメーター、クラス メンバーの初期化、およびポインターと参照に関するものです。

常に const 参照によってパラメーターを取得します (Gunter Königsmann)
関数がパラメーターを受け取り、それを変更したくない場合、2 つのオプションがあります。
- パラメータを値で取得 (コピー)
- const 参照によるパラメータの取得
これは正しさの観点でしたが、パフォーマンスについて言えることは何ですか。 C++ コア ガイドラインは、パフォーマンスに特化しています。次の例を見てみましょう。
void f1(const string& s); // OK: pass by reference to const; always cheap void f2(string s); // bad: potentially expensive void f3(int x); // OK: Unbeatable void f4(const int& x); // bad: overhead on access in f4()
おそらく、経験に基づいて、ガイドラインは経験則を述べています:
- sizeof(p)> 4 * sizeof(int) の場合、const 参照によってパラメータ p を取得する必要があります
- sizeof(p) <3 * sizeof(int) の場合、パラメータ p をコピーする必要があります
さて、これでデータ型の大きさがわかったはずです。プログラム sizeofArithmeticTypes.cpp は、算術型の答えを提供します。
// sizeofArithmeticTypes.cpp
#include <iostream>
int main(){
std::cout << std::endl;
std::cout << "sizeof(void*): " << sizeof(void*) << std::endl;
std::cout << std::endl;
std::cout << "sizeof(5): " << sizeof(5) << std::endl;
std::cout << "sizeof(5l): " << sizeof(5l) << std::endl;
std::cout << "sizeof(5ll): " << sizeof(5ll) << std::endl;
std::cout << std::endl;
std::cout << "sizeof(5.5f): " << sizeof(5.5f) << std::endl;
std::cout << "sizeof(5.5): " << sizeof(5.5) << std::endl;
std::cout << "sizeof(5.5l): " << sizeof(5.5l) << std::endl;
std::cout << std::endl;
}
sizeof(void*) は、32 ビット システムか 64 ビット システムかを返します。オンライン コンパイラ rextester のおかげで、GCC、Clang、および cl.exe (Windows) でプログラムを実行できます。すべての 64 ビット システムの数値は次のとおりです。
GCC

クラン

cl.exe (Windows)

cl.exe は、GCC および Clang とは異なる動作をします。 long int は 4 バイトしかなく、long double は 8 バイトです。 GCC と Clang では、long int と long double のサイズは double です。
パラメータをいつ値または const 参照で取得するかを決定するには、単なる数学です。アーキテクチャの正確なパフォーマンス数値を知りたい場合、答えは 1 つだけです:測定 .
コンストラクタでの初期化と代入は同等です (Gunter Königsmann)
まず、コンストラクターでの初期化と代入をお見せしましょう。
class Good{
int i;
public:
Good(int i_): i{i_}{}
};
class Bad{
int i;
public:
Bad(int i_): { i = i_; }
};
クラス Good は初期化を使用しますが、クラス Bad 割り当てを使用します。結果は次のとおりです:
- 変数 i はクラス Good で直接初期化されます
- 変数 i はデフォルトで作成され、Bad クラスに割り当てられます
コンストラクターの初期化は、一方では遅くなりますが、他方では、デフォルトで構築できない const メンバー、参照、またはメンバーに対しては機能しません。
// constructorAssignment.cpp
struct NoDefault{
NoDefault(int){};
};
class Bad{
const int constInt;
int& refToInt;
NoDefault noDefault;
public:
Bad(int i, int& iRef){
constInt = i;
refToInt = iRef;
}
// Bad(int i, int& iRef): constInt(i), refToInt(iRef), noDefault{i} {}
};
int main(){
int i = 10;
int& j = i;
Bad bad(i, j);
}
プログラムをコンパイルしようとすると、3 つの異なるエラーが発生します。
<オール>
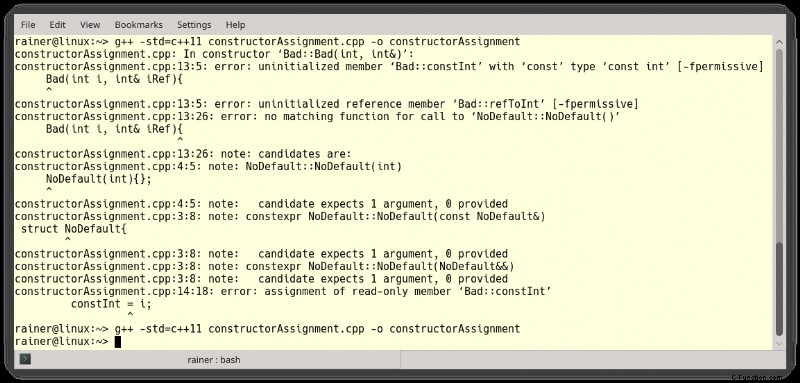
2 番目の成功したコンパイルでは、割り当ての代わりに初期化を使用する 2 番目のコメント アウトされたコンストラクターを使用しました。
この例では、正当な理由により、生のポインターの代わりに参照を使用しました。
コードに未加工のポインターが必要です (Thargon110)
Thargon110 からのコメントに動機付けられて、独断的になりたい:NNN.何?つまり N o ナ ケド N うーん。アプリケーションの観点からは、生のポインターを使用する理由はありません。セマンティックのようなポインターが必要な場合は、ポインターをスマート ポインター (NNN を参照) に配置すれば完了です。
本質的に、C++11 には排他的所有権のための std::unique_ptr と共有所有権のための std::shared_ptr があります。したがって、std::shared_ptr をコピーすると参照カウンターが増加し、std::shared_ptr を削除すると参照カウンターが減少します。所有権とは、スマート ポインターが基礎となるメモリを追跡し、必要がなくなった場合にメモリを解放することを意味します。 std::shared_ptr の場合、参照カウンタが 0 になるとメモリは不要になります。
そのため、最新の C++ ではメモリ リークはなくなりました。今、私はあなたの不満を聞きます。喜んでそれらを破壊します。
- 参照カウンタが 0 にならないため、std::shared_ptr のサイクルによってメモリ リークが発生する可能性があります。そうです、循環参照 std::weak_ptr を壊すために、間に std::weak_ptr を配置します。
- std::shared_ptr には管理オーバーヘッドがあるため、生のポインターよりもコストがかかります。そうです、std::unique_ptr を使用してください。
- std::unique_ptr はコピーできないため、快適ではありません。そうです、しかし std::unique_ptr は移動できます。
最後の苦情は非常に支配的です。ちょっとした例が私の言いたいことを表しているはずです:
// moveUniquePtr.cpp
#include <algorithm>
#include <iostream>
#include <memory>
#include <utility>
#include <vector>
void takeUniquePtr(std::unique_ptr<int> uniqPtr){ // (1)
std::cout << "*uniqPtr: " << *uniqPtr << std::endl;
}
int main(){
std::cout << std::endl;
auto uniqPtr1 = std::make_unique<int>(2014);
takeUniquePtr(std::move(uniqPtr1)); // (1)
auto uniqPtr2 = std::make_unique<int>(2017);
auto uniqPtr3 = std::make_unique<int>(2020);
auto uniqPtr4 = std::make_unique<int>(2023);
std::vector<std::unique_ptr<int>> vecUniqPtr;
vecUniqPtr.push_back(std::move(uniqPtr2)); // (2)
vecUniqPtr.push_back(std::move(uniqPtr3)); // (2)
vecUniqPtr.push_back(std::move(uniqPtr4)); // (2)
std::cout << std::endl;
std::for_each(vecUniqPtr.begin(), vecUniqPtr.end(), // (3)
[](std::unique_ptr<int>& uniqPtr){ std::cout << *uniqPtr << std::endl; } );
std::cout << std::endl;
}
行 (1) の関数 takeUniquePtr は、std::unique_ptr を値で受け取ります。重要な観察は、 std::unique_ptr を内部に移動する必要があることです。同じ引数が std::vector
未加工ポインタの代わりに参照を使用する
最後に、Thargon110 の重要な懸念事項について言及したいと思います。確かに、スマート ポインターは未加工のポインターの所有者とは対照的であるため、スマート ポインターを使用しない従来の C++ では、この規則がはるかに重要です。
参照には常に値があるため、ポインターの代わりに参照を使用します。次のような退屈なチェックは、参照とともになくなりました。
if(!ptr){
std::cout << "Something went terrible wrong" << std::endl;
return;
}
std::cout << "All fine" << std::endl;
さらに、チェックを忘れることがあります。参照は、定数ポインターと同じように動作します。
次は?
C++ コア ガイドラインではプロファイルが定義されています。プロファイルはルールのサブセットです。それらは、型の安全性、境界の安全性、および生涯の安全性のために存在します。それらは私の次のトピックになります。