私の当初の計画は、C++ コア ガイドラインのルールについて正規表現とクロノ ライブラリに書くことでしたが、サブセクションのタイトル以外に利用できるコンテンツはありません。時間機能については、すでにいくつかの記事を書いています。だから私は終わった。今日は、ギャップを埋めて正規表現ライブラリについて書きます。

わかりました、これが私の正規表現のルールです。
必要な場合にのみ正規表現を使用してください
正規表現は強力ですが、テキストを操作するための高価で複雑な機械でもあります。 std::string のインターフェースまたは標準テンプレート ライブラリのアルゴリズムが機能する場合は、それらを使用します。
わかりましたが、いつ正規表現を使用する必要がありますか?一般的な使用例は次のとおりです。
正規表現のユースケース
- テキストがテキスト パターンと一致するかどうかを確認します:std::regex_match
- テキスト内のテキスト パターンを検索:std::regex_search
- テキスト パターンをテキストに置き換えます:std::regex_replace
- テキスト内のすべてのテキスト パターンを反復処理:std::regex_iterator および std::regex_token_iterator
あなたがそれに気づいたことを願っています。操作は、テキストではなく、テキスト パターンに対して機能します。
まず、生の文字列を使用して正規表現を記述する必要があります。
正規表現に未加工の文字列を使用する
まず、簡単にするために、前の規則を破ります。
テキスト C++ の正規表現は、C\\+\\+ という非常に醜いものです。 + 記号ごとに 2 つのバックスラッシュを使用する必要があります。まず、+ 記号は正規表現の特殊文字です。次に、バックスラッシュは文字列内の特殊文字です。したがって、バックスラッシュの 1 つは + 記号をエスケープし、もう 1 つのバックスラッシュはバックスラッシュをエスケープします。
生の文字列リテラルを使用すると、バックスラッシュは文字列内で解釈されないため、2 番目のバックスラッシュは不要になります。
次の短い例では納得できないかもしれません.
std::string regExpr("C\\+\\+");
std::string regExprRaw(R"(C\+\+)");
両方の文字列は、テキスト C++ に一致する正規表現を表します。特に、生の文字列 R"(C\+\+) は非常に読みにくいです。R"( 生の文字列)" 生の文字列を区切ります。ちなみに、Windows の正規表現とパス名 "C:\temp\newFile.txt" は、生の文字列の典型的な使用例です。
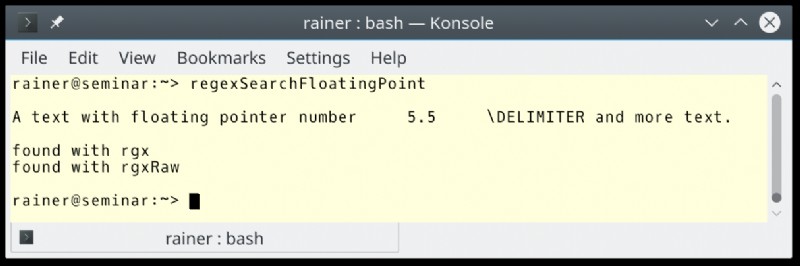
テキスト内の浮動小数点数を検索したいとします。これは、次の一連の記号で識別されます:Tabulator FloatingPointNumber Tabulator \\DELIMITER.このパターンの具体例は次のとおりです:"\t5.5\t\\DELIMITER".
次のプログラムは、文字列と生の文字列で正規表現エンコードを使用して、このパターンに一致させます。
// regexSearchFloatingPoint.cpp
#include <regex>
#include <iostream>
#include <string>
int main(){
std::cout << std::endl;
std::string text = "A text with floating pointer number \t5.5\t\\DELIMITER and more text.";
std::cout << text << std::endl;
std::cout << std::endl;
std::regex rgx("\\t[0-9]+\\.[0-9]+\\t\\\\DELIMITER"); // (1)
std::regex rgxRaw(R"(\t[0-9]+\.[0-9]+\t\\DELIMITER)"); // (2)
if (std::regex_search(text, rgx)) std::cout << "found with rgx" << std::endl;
if (std::regex_search(text, rgxRaw)) std::cout << "found with rgxRaw" << std::endl;
std::cout << std::endl;
}
正規表現 rgx("\\t[0-9]+\\.[0-9]+\\t\\\\DELIMITER") かなり醜いです。 n "\ を検索するには "-symbols (行 1)、2 * n "\"-symbols を記述する必要があります。対照的に、生の文字列を使用して正規表現を定義すると、探しているパターンを正規表現で直接表現することが可能になります。式:rgxRaw(R"(\t[0-9]+\.[0-9]+\t\\DELIMITER)") (2行目)。部分式 [0-9]+\.[0-9]+ 正規表現の は浮動小数点数を表します:少なくとも 1 つの数値 [0-9]+ その後にドット \. 少なくとも 1 つの数字が続く [0-9]+ .
完全を期すために、プログラムの出力を示します。
正直なところ、この例はかなり単純でした。ほとんどの場合、試合結果を分析する必要があります。
さらに分析するには、match_result を使用してください
正規表現の使用は、通常、3 つのステップで構成されます。これは std::regex_search と std::regex_match に当てはまります。
<オール>それが何を意味するか見てみましょう。今回は文中の最初のメールアドレスを探したいと思います。次の電子メール アドレスの正規表現 (RFC 5322 公式規格) は、非常に不規則であるため、すべての電子メール アドレスを検出するわけではありません。
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[az0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x2\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")
@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
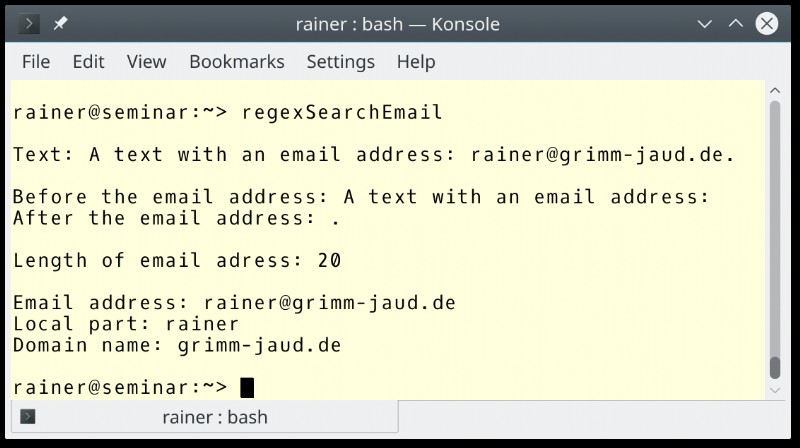
読みやすくするために、正規表現に改行を入れました。最初の行は電子メール アドレスのローカル部分に一致し、2 行目はドメイン部分に一致します。私のプログラムは、より単純な正規表現を使用して電子メール アドレスを照合します。完璧ではありませんが、その役割を果たします。さらに、電子メール アドレスのローカル部分とドメイン部分を一致させたいと考えています。
// regexSearchEmail.cpp
#include <regex>
#include <iostream>
#include <string>
int main(){
std::cout << std::endl;
std::string emailText = "A text with an email address: This email address is being protected from spambots. You need JavaScript enabled to view it..";
// (1)
std::string regExprStr(R"(([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4}))");
std::regex rgx(regExprStr);
// (2)
std::smatch smatch;
if (std::regex_search(emailText, smatch, rgx)){
// (3)
std::cout << "Text: " << emailText << std::endl;
std::cout << std::endl;
std::cout << "Before the email address: " << smatch.prefix() << std::endl;
std::cout << "After the email address: " << smatch.suffix() << std::endl;
std::cout << std::endl;
std::cout << "Length of email adress: " << smatch.length() << std::endl;
std::cout << std::endl;
std::cout << "Email address: " << smatch[0] << std::endl; // (6)
std::cout << "Local part: " << smatch[1] << std::endl; // (4)
std::cout << "Domain name: " << smatch[2] << std::endl; // (5)
}
std::cout << std::endl;
}
行 1、2、および 3 は、正規表現の使用の 3 つの典型的なステップの開始を表します。 2 行目の正規表現には、さらにいくつかの単語が必要です。
ここにあります:([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4})
- [\w.%+-]+ :次の文字の少なくとも 1 つ:"\w"、"."、"%"、"+"、 または "-". "\w" 単語の文字を表します。
- [\w.-]+\.[a-zA-Z]{2,4} :「\w」、「.」、「-」の少なくとも 1 つ 、その後にドット "." 、続いて 2 - 4 a-z の範囲の文字 または範囲 A-Z.。
- (...)@(...) :丸括弧はキャプチャ グループを表します。それらを使用すると、一致のサブマッチを識別できます。最初のキャプチャ (4 行目) グループは、アドレスのローカル部分です。 2 番目のキャプチャ グループ (5 行目) は、電子メール アドレスのドメイン部分です。 0 番目のキャプチャ グループ (6 行目) で試合全体に対処できます。
プログラムの出力は、詳細な分析を示しています。
次は?
まだ終わらない。正規表現については、次回の投稿でさらに書きます。さまざまな種類のテキストと、すべての一致を繰り返すことについて書いています。