C++ 標準ライブラリの規則は、主にコンテナー、文字列、および iostream に関するものです。

奇妙なことに、この章には標準テンプレート ライブラリ (STL) のアルゴリズムに関するセクションはありません。不思議なことに、C++ コミュニティには次のことわざがあります。明示的なループを作成すると、STL のアルゴリズムはわかりません。ともかく。完全を期すために、最初の 3 つのルールから始めましょう。これらのルールはあまり役に立ちません。
SL.1:車輪の再発明は悪い考えなので、可能な限りライブラリを使用します。さらに、他の人の仕事からも恩恵を受けます。これは、すでにテスト済みで明確に定義された機能を使用することを意味します。これは特に、SL.2:標準ライブラリを他のライブラリよりも優先する場合に当てはまります。たとえば、誰かを雇ったとします。利点は、彼がすでにライブラリを知っているため、ライブラリを教える必要がないことです。多くのお金と時間を節約できます。以前、インフラストラクチャの名前空間を std と名付けた顧客がいました。もちろん、たくさん楽しみたいなら、やりましょう。そうでない場合:SL.3:非標準エンティティを名前空間 std に追加しないでください .
STL コンテナの次のルールはより具体的です。
コンテナ
最初のルールは非常に簡単に議論できます。
SL.con.1:STL の使用を優先 array または vector C配列の代わり
std::vector を知っていると思います。 C 配列に対する std::vector の大きな利点の 1 つは、std::vector がそのメモリを自動的に管理することです。もちろん、それは標準テンプレート ライブラリのその他のすべてのコンテナにも当てはまります。しかしここで、std::vector の自動メモリ管理を詳しく見てみましょう。
std::vector
// vectorMemory.cpp
#include <iostream>
#include <string>
#include <vector>
template <typename T>
void showInfo(const T& t,const std::string& name){
std::cout << name << " t.size(): " << t.size() << std::endl;
std::cout << name << " t.capacity(): " << t.capacity() << std::endl;
}
int main(){
std::cout << std::endl;
std::vector<int> vec; // (1)
std::cout << "Maximal size: " << std::endl;
std::cout << "vec.max_size(): " << vec.max_size() << std::endl; // (2)
std::cout << std::endl;
std::cout << "Empty vector: " << std::endl;
showInfo(vec, "Vector");
std::cout << std::endl;
std::cout << "Initialised with five values: " << std::endl;
vec = {1,2,3,4,5};
showInfo(vec, "Vector"); // (3)
std::cout << std::endl;
std::cout << "Added four additional values: " << std::endl;
vec.insert(vec.end(),{6,7,8,9});
showInfo(vec,"Vector"); // (4)
std::cout << std::endl;
std::cout << "Resized to 30 values: " << std::endl;
vec.resize(30);
showInfo(vec,"Vector"); // (5)
std::cout << std::endl;
std::cout << "Reserved space for at least 1000 values: " << std::endl;
vec.reserve(1000);
showInfo(vec,"Vector"); // (6)
std::cout << std::endl;
std::cout << "Shrinke to the current size: " << std::endl;
vec.shrink_to_fit(); // (7)
showInfo(vec,"Vector");
}
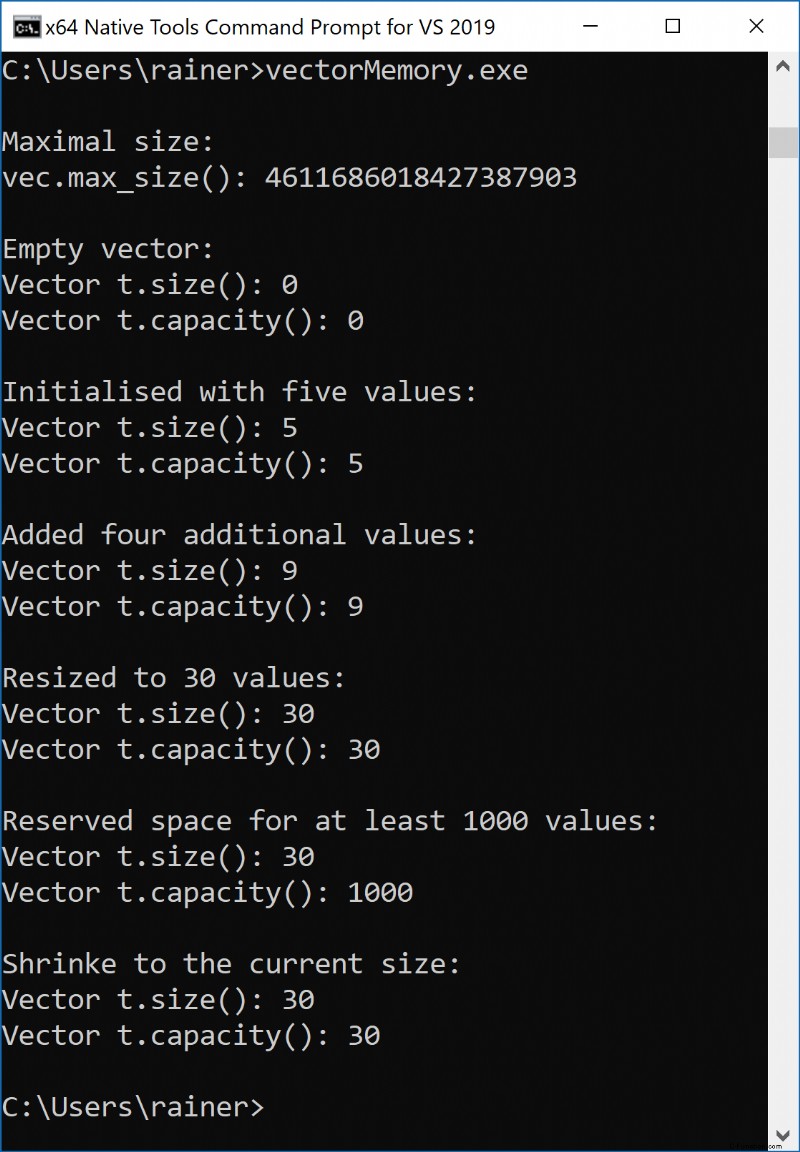
入力を省くために、小さな関数 showInfo を書きました。この関数は、ベクトルのサイズと容量を返します。ベクトルのサイズはその要素の数であり、コンテナーの容量は、追加のメモリ割り当てなしでベクトルが保持できる要素の数です。したがって、ベクトルの容量は、少なくともそのサイズと同じ大きさでなければなりません。ベクトルのサイズは resize メソッドで調整できます。メソッドリザーブでコンテナの容量を調整できます。
しかし、プログラムを上から下に戻します。 (1 行目) 空のベクターを作成します。その後、プログラムはベクトルが持つことができる要素の最大数を表示します (2 行目)。各操作の後、サイズと容量を返します。これは、ベクトルの初期化 (3 行目)、4 つの新しい要素の追加 (4 行目)、コンテナーのサイズを 30 要素に変更 (5 行目)、および少なくとも 1000 要素用の追加メモリの予約 (行 6)。 C++11 では、shrink_to_fit メソッド (7 行目) を使用して、ベクターの容量をそのサイズに縮小できます。
Linux でのプログラムの出力を提示する前に、いくつかコメントさせてください。
<オール>
わかりましたが、C 配列と C++ 配列の違いは何ですか?
std::array
std::array は、2 つの世界から最高のものを組み合わせます。一方では、std::array は C 配列のサイズと効率を備えています。一方、std::array には std::vector のインターフェースがあります。
私の小さなプログラムは、C 配列、C++ 配列 (std::array)、および std::vector のメモリ効率を比較します。
// sizeof.cpp
#include <iostream>
#include <array>
#include <vector>
int main(){
std::cout << std::endl;
std::cout << "sizeof(int)= " << sizeof(int) << std::endl;
std::cout << std::endl;
int cArr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::array<int, 10> cppArr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::vector<int> cppVec = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::cout << "sizeof(cArr)= " << sizeof(cArr) << std::endl; // (1)
std::cout << "sizeof(cppArr)= " << sizeof(cppArr) << std::endl; // (2)
// (3)
std::cout << "sizeof(cppVec) = " << sizeof(cppVec) + sizeof(int) * cppVec.capacity() << std::endl;
std::cout << " = sizeof(cppVec): " << sizeof(cppVec) << std::endl;
std::cout << " + sizeof(int)* cppVec.capacity(): " << sizeof(int)* cppVec.capacity() << std::endl;
std::cout << std::endl;
}
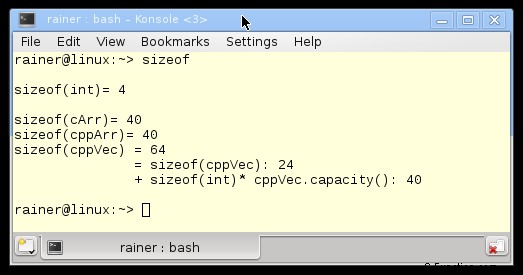
C 配列 (1 行目) と C++ 配列 (2 行目) はどちらも 40 バイトを使用します。これは正確に sizeof(int) * 10 です。対照的に、std::vector は、ヒープ上のデータを管理するために追加の 24 バイト (3 行目) を必要とします。
これは std::array の C 部分でしたが、std::array は std::vector のインターフェースをサポートしています。これは、特に、std::array がそのサイズを認識していることを意味します。したがって、次のようなエラーが発生しやすいインターフェイスは、コード臭が強いです。
void bad(int* p, int count){
...
}
int myArray[100] = {0};
bad(myArray, 100);
// -----------------------------
void good(std::array<int, 10> arr){
...
}
std::array<int, 100> myArray = {0};
good(myArray);
C 配列を関数の引数として使用する場合、ほとんどすべての型情報を削除し、最初の引数へのポインターとして渡します。要素の数を追加で指定する必要があるため、これは非常にエラーが発生しやすくなります。関数が std::array
機能が十分に一般的でない場合は、テンプレートを使用できます。
template <typename T>
void foo(T& arr){
arr.size(); // (1)
}
std::array<int, 100> arr{};
foo(arr);
std::array<double, 20> arr2{};
foo(arr2);
std::array はそのサイズを知っているので、1 行目でそれを要求できます。
次は?
コンテナーに関する次の 2 つのルールは非常に興味深いものです。次の投稿では、次の質問に答えます:どのコンテナーをいつ使用するか?