今日は、テンプレートの残りのいくつかのルールについて書きます。集合名が欠落しているため、セクション other のテンプレートに異種ルールを配置します。ルールはベスト プラクティスに関するものですが、サプライズに関するものでもあります。

この投稿のルールは次のとおりです。
- T.140:再利用の可能性があるすべての操作の名前を挙げてください
- T.141:単純な関数オブジェクトが 1 か所だけ必要な場合は、名前のないラムダを使用してください
- T.143:意図せずに汎用性のないコードを記述しない
最初のルールは、ベスト プラクティスに関するものです。
T.140:再利用の可能性があるすべての操作に名前を付けてください
正直なところ、なぜこのルールがテンプレートに属するのかよくわかりません。おそらくテンプレートは再利用に関するものか、ガイドラインの例では標準テンプレート ライブラリの std::find_if アルゴリズムを使用しています。とにかく、このルールはコード品質の観点からは基本的なものです.
レコードのベクトルがあるとします。各レコードは、名前、アドレス、および ID で構成されます。多くの場合、特定の名前を持つレコードを見つけたいと思うでしょう。ただし、さらに難しくするために、名前の大文字と小文字の区別を無視します。
// records.cpp
#include <algorithm>
#include <cctype>
#include <iostream>
#include <string>
#include <vector>
struct Rec { // (1)
std::string name;
std::string addr;
int id;
};
int main(){
std::cout << std::endl;
std::vector<Rec> vr{ {"Grimm", "Munich", 1}, // (2)
{"huber", "Stuttgart", 2},
{"Smith", "Rottenburg", 3},
{"black", "Hanover", 4} };
std::string name = "smith";
auto rec = std::find_if(vr.begin(), vr.end(), [&](Rec& r) { // (3)
if (r.name.size() != name.size()) return false;
for (int i = 0; i < r.name.size(); ++i){
if (std::tolower(r.name[i]) != std::tolower(name[i])) return false;
}
return true;
});
if (rec != vr.end()){
std::cout << rec->name << ", " << rec->addr << ", " << rec->id << std::endl;
}
std::cout << std::endl;
}
構造体 Rec (1 行目) には public メンバーしかありません。したがって、集約初期化を使用して、すべてのメンバーを行 (2) で直接初期化できます。インライン (3) ラムダ関数を使用して、「smith」という名前のレコードを検索します。最初に、両方の名前が同じサイズであるかどうかを確認し、次に、大文字と小文字を区別せずに比較したときに文字が同一であるかどうかを確認します。
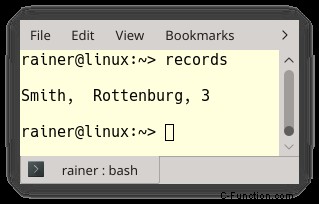
コードの問題は何ですか?文字列の大文字と小文字を区別しない比較の要件はあまりにも一般的であるため、解決策をオブジェクトに入れ、名前を付けて再利用する必要があります。
bool compare_insensitive(const std::string& a, const std::string& b) // (1)
{
if (a.size() != b.size()) return false;
for (int i = 0; i < a.size(); ++i){
if (std::tolower(a[i]) != std::tolower(b[i])) return false;
}
return true;
}
std::string name = "smith";
auto res = std::find_if(vr.begin(), vr.end(),
[&](Rec& r) { compare_insensitive(r.name, name); }
);
std::vector<std::string> vs{"Grimm", "huber", "Smith", "black"}; // (2)
auto res2 = std::find_if(vs.begin(), vs.end(),
[&](std::string& r) { compare_insensitive(r, name); }
);
関数 compare_insensitive (1 行目) は、一般的な概念に名前を付けます。これで、文字列のベクトルに使用できます (2 行目)。
T.141:名前のないラムダを使用する単純な関数オブジェクトが 1 か所だけ必要な場合
確かに、私は自分のクラスでよくこの議論をしています:関数 (関数オブジェクト) またはラムダ関数はいつ使用する必要がありますか?正直なところ、簡単な答えはありません。ここでは、コード品質の 2 つのメタルールが矛盾しています:
<オール>申し訳ありませんが、Python から 2 番目のポイントをお借りしました。しかし、それはどういう意味ですか?あなたのチームに昔ながらの Fortran プログラマーがいて、彼が「名前はそれぞれ 3 文字でなければなりません」と言ったとします。したがって、次のコードで終了します。
auto eUE = std::remove_if(use.begin(), use.end(), igh);
igh という名前は何の略ですか? igh は 100 より大きい ID を表します。ここで、述語の使用法を文書化する必要があります。
ただし、ラムダ関数を使用すると、コード自体が文書化されます。
auto earlyUsersEnd = std::remove_if(users.begin(), users.end(),
[](const User &user) { return user.id > 100; });
私を信じてください;名前について Fortran プログラマーと話し合いました。確かに、コードの局所性とコードのサイズなど、ラムダ関数の賛否両論はありますが、「同じことを繰り返さないでください」と「明示的は暗黙的よりも優れている」が私の主要な議論です。
T.143:意図せずに非ジェネリック コードを記述しない
短い例は、長い説明以上のものを物語っています。次の例では、std::vector、std::deque、および std::list を反復処理します。
// notGeneric.cpp
#include <deque>
#include <list>
#include <vector>
template <typename Cont>
void justIterate(const Cont& cont){
const auto itEnd = cont.end();
for (auto it = cont.begin(); it < itEnd; ++it) { // (1)
// do something
}
}
int main(){
std::vector<int> vecInt{1, 2, 3, 4, 5};
justIterate(vecInt); // (2)
std::deque<int> deqInt{1, 2, 3, 4, 5};
justIterate(deqInt); // (3)
std::list<int> listInt{1, 2, 3, 4, 5};
justIterate(listInt); // (4)
}
コードは無害に見えますが、プログラムをコンパイルしようとすると、コンパイルが失敗します。約 100 行のエラー メッセージが表示されます。
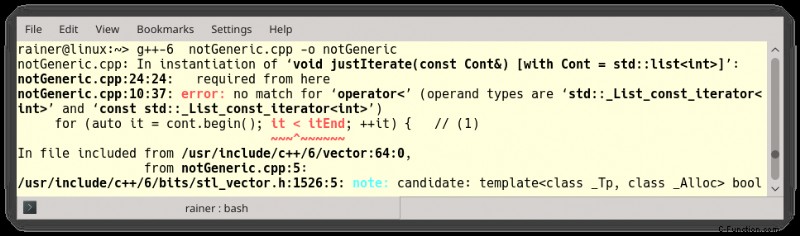
エラー メッセージの冒頭で、「notGeneric.cpp:10:37:error:no match for 'operator<' (オペランド タイプは 'std::_List_const_iterator" です。
どうした?問題は行 (1) にあります。イテレータ比較 (<) は、std::vector (2 行目) と std::deque (3 行目) では機能しますが、std::list (4 行目) では機能しません。各コンテナは、その構造を表す反復子を返します。これは、std::vector と std::deque の場合はランダム アクセス イテレータであり、std::list の場合は双方向イテレータです。イテレータ カテゴリを見ると、非常に役立ちます。

ランダム アクセス反復子カテゴリは双方向反復子カテゴリのスーパーセットであり、双方向反復子カテゴリは順方向反復子カテゴリのスーパーセットです。さて、問題は明らかです。リストで指定された反復子は、より小さい比較をサポートしていません。バグを修正するのはとても簡単です。各反復子カテゴリの反復子は、!=比較をサポートしています。これが修正された justIterate 関数テンプレートです。
template <typename Cont>
void justIterate(const Cont& cont){
const auto itEnd = cont.end();
for (auto it = cont.begin(); it != itEnd; ++it) { // (1)
// do something
}
}
ところで、私が関数 justIterate で行っているように、コンテナーをループ処理することは、通常は悪い考えです。これは、標準テンプレート ライブラリの適切なアルゴリズムの仕事です。
次は?
私の当初の計画では、今日はルール T.144:関数テンプレートを特殊化しないことについても書く予定でした。このルールには大きな驚きの可能性があります。次の投稿で、私の言いたいことがわかるでしょう。