並行性は、自分自身を撃つ多くの方法を提供します。今日のルールは、これらの危険を知り、克服するのに役立ちます。

まず、この投稿の 3 つのルールを次に示します。
- CP.31:参照やポインタではなく、値によってスレッド間で少量のデータを受け渡します
- CP.32:関係のない
thread間で所有権を共有するにはshared_ptrを使用します - CP.41:スレッドの作成と破棄を最小限に抑える
内容がないので無視するルールです。
CP.31:小さいパス参照やポインターではなく、値によるスレッド間のデータ量
この規則は非常に明白です。したがって、私はそれを短くすることができます。データを値でスレッドに渡すと、次の 2 つのメリットがすぐに得られます。
<オール>
もちろん、重要な問題は次のとおりです。少量のデータは何を意味するのでしょうか。 C++ コア ガイドラインは、この点について明確ではありません。ルール F.16 では、「in」パラメータについては、安価にコピーされた型を値で渡し、その他は const to functions, への参照で渡します。 C++ コア ガイドラインでは、4 * sizeof(int) が関数の経験則であると述べています。つまり、4 * sizeof(int) より小さい値は値で渡す必要があります。参照またはポインタによる 4 * sizeof(int) より大きい。
最後に、必要に応じてパフォーマンスを測定する必要があります。
CP.32:関係のない thread 間で所有権を共有するには shared_ptr を使用します
無関係なスレッド間で共有したいオブジェクトがあると想像してください。重要な問題は、オブジェクトの所有者は誰で、したがってメモリを解放する責任があるのは誰かということです。これで、メモリの割り当てを解除しないとメモリ リークが発生するか、delete を複数回呼び出したために未定義の動作が発生するかを選択できるようになりました。ほとんどの場合、未定義の動作はランタイム クラッシュで終了します。
// threadSharesOwnership.cpp
#include <iostream>
#include <thread>
using namespace std::literals::chrono_literals;
struct MyInt{
int val{2017};
~MyInt(){ // (4)
std::cout << "Good Bye" << std::endl;
}
};
void showNumber(MyInt* myInt){
std::cout << myInt->val << std::endl;
}
void threadCreator(){
MyInt* tmpInt= new MyInt; // (1)
std::thread t1(showNumber, tmpInt); // (2)
std::thread t2(showNumber, tmpInt); // (3)
t1.detach();
t2.detach();
}
int main(){
std::cout << std::endl;
threadCreator();
std::this_thread::sleep_for(1s);
std::cout << std::endl;
}
我慢してください。この例は意図的に簡単にしています。メイン スレッドを 1 秒間スリープさせて、子スレッド t1 と t2 の寿命を確実に延ばします。もちろん、これは適切な同期ではありませんが、私の主張を理解するのに役立ちます。このプログラムの重要な問題は次のとおりです。tmpInt (1) の削除の責任者は誰ですか?スレッド t1 (2)、スレッド t2 (3)、または関数 (メイン スレッド) 自体。各スレッドの実行時間を予測できないため、メモリ リークを使用することにしました。したがって、MyInt (4) のデストラクタは呼び出されません:
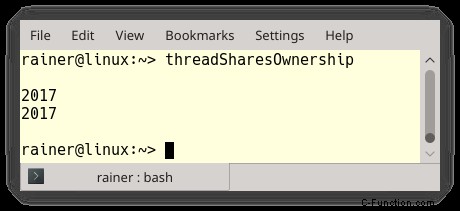
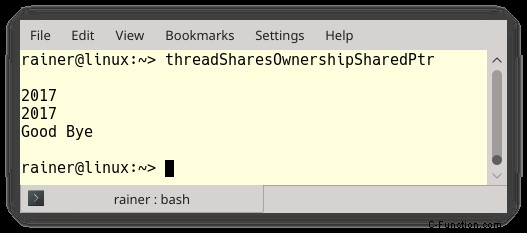
std::shared_ptr を使用すれば、ライフタイムの問題は非常に簡単に処理できます。
// threadSharesOwnershipSharedPtr.cpp
#include <iostream>
#include <memory>
#include <thread>
using namespace std::literals::chrono_literals;
struct MyInt{
int val{2017};
~MyInt(){
std::cout << "Good Bye" << std::endl;
}
};
void showNumber(std::shared_ptr<MyInt> myInt){ // (2)
std::cout << myInt->val << std::endl;
}
void threadCreator(){
auto sharedPtr = std::make_shared<MyInt>(); // (1)
std::thread t1(showNumber, sharedPtr);
std::thread t2(showNumber, sharedPtr);
t1.detach();
t2.detach();
}
int main(){
std::cout << std::endl;
threadCreator();
std::this_thread::sleep_for(1s);
std::cout << std::endl;
}
ソース コードに 2 つの小さな変更が必要でした。まず、(1) のポインターが std::shared_ptr になり、次に、関数 showNumber がプレーン ポインターの代わりにスマート ポインターを受け取ります。
CP.41:スレッドの作成と破棄を最小限に抑える
糸の値段は?すごく高価!これがこのルールの背後にある問題です。最初にスレッドの通常のサイズについて話してから、その作成のコストについて話しましょう。
サイズ
std::thread は、ネイティブ スレッドの薄いラッパーです。これは、Windows スレッドと POSIX スレッドのサイズに関心があることを意味します。
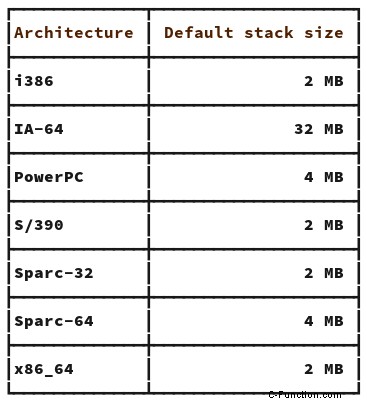
- Windows システム:スレッド スタック サイズの投稿で、答えは 1 MB でした。
- POSIX システム:pthread_create のマンページに 2MB という答えがあります。これは、i386 および x86_64 アーキテクチャのサイズです。 POSIX をサポートするその他のアーキテクチャのサイズを知りたい場合は、次のとおりです。
創造
スレッドを作成するのに時間がかかる数字は見つかりませんでした。直感をつかむために、Linux と Windows で簡単なパフォーマンス テストを行いました。
デスクトップでは GCC 6.2.1 を使用し、ラップトップでは cl.exe をパフォーマンス テストに使用しました。 cl.exe は Microsoft Visual Studio 2017 の一部です。プログラムは最大限に最適化してコンパイルしました。これは、Linux では O3 フラグ、Windows では Ox フラグを意味します。
これが私の小さなテスト プログラムです。
// threadCreationPerformance.cpp
#include <chrono>
#include <iostream>
#include <thread>
static const long long numThreads= 1000000;
int main(){
auto start = std::chrono::system_clock::now();
for (volatile int i = 0; i < numThreads; ++i) std::thread([]{}).detach(); // (1)
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "time: " << dur.count() << " seconds" << std::endl;
}
このプログラムは、空のラムダ関数を実行する 100 万個のスレッドを作成します (1)。 Linux と Windows の数値は次のとおりです:
Linux:
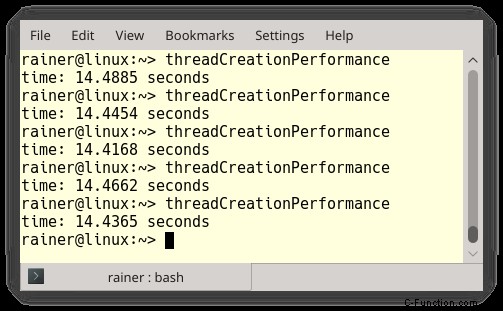
これは、スレッドの作成に約 14.5 秒 / 1000000 =Linux で 14.5 マイクロ秒 かかったということです。 .
Windows:
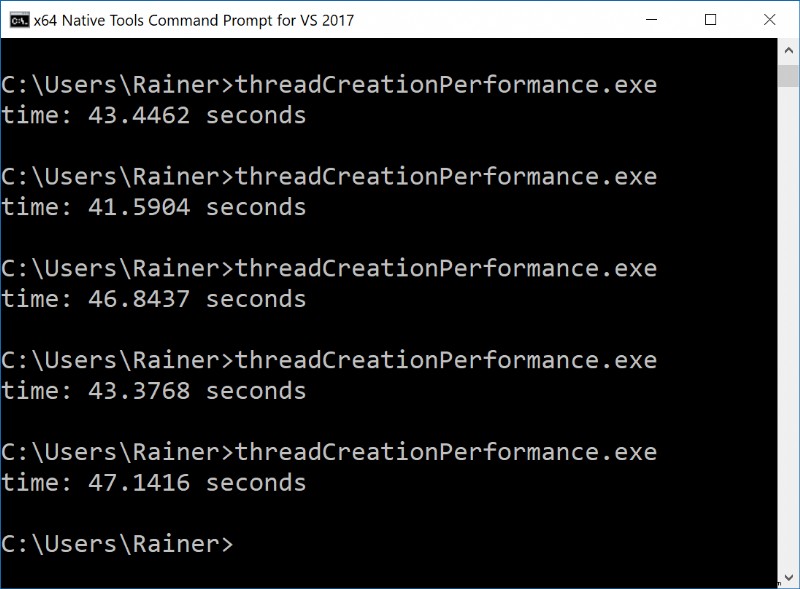
約 44 秒 / 1000000 =Windows では 44 マイクロ秒かかりました。
逆に言えば。 1 秒間に、 Linux で約 69,000 スレッド、Windows で 23,000 スレッドを作成できます。
次は?
自分の足を撃つ最も簡単な方法は何ですか?条件変数を使おう!信じられない?次の投稿をお待ちください!