この投稿では、C++ コア ガイドラインのルールからパフォーマンスまでの旅を続けます。主に最適化のための設計について書いていきます。

本日のルールはこの2つ。
- Per.7:最適化を可能にする設計
- Per.10:静的型システムに頼る
Per.7:最適化を可能にする設計
このタイトルを読んだとき、私はすぐに動きのセマンティクスについて考えなければなりません。なんで?コピー セマンティックではなく、ムーブ セマンティックを使用してアルゴリズムを記述する必要があるためです。自動的にいくつかのメリットが得られます。
<オール>了解した!移動セマンティクスを使用する一般的なスワップ アルゴリズムを実装してみましょう。
// swap.cpp
#include <algorithm>
#include <cstddef>
#include <iostream>
#include <vector>
template <typename T> // (3)
void swap(T& a, T& b) noexcept {
T tmp(std::move(a));
a = std::move(b);
b = std::move(tmp);
}
class BigArray{
public:
BigArray(std::size_t sz): size(sz), data(new int[size]){}
BigArray(const BigArray& other): size(other.size), data(new int[other.size]){
std::cout << "Copy constructor" << std::endl;
std::copy(other.data, other.data + size, data);
}
BigArray& operator=(const BigArray& other){ // (1)
std::cout << "Copy assignment" << std::endl;
if (this != &other){
delete [] data;
data = nullptr;
size = other.size;
data = new int[size];
std::copy(other.data, other.data + size, data);
}
return *this;
}
~BigArray(){
delete[] data;
}
private:
std::size_t size;
int* data;
};
int main(){
std::cout << std::endl;
BigArray bigArr1(2011);
BigArray bigArr2(2017);
swap(bigArr1, bigArr2); // (2)
std::cout << std::endl;
};
罰金。それだけでした。いいえ!同僚が彼の型 BigArray をくれました。 BigArray にはいくつかの欠陥があります。コピー代入演算子(1)については後ほど書きます。まず、もっと深刻な懸念があります。 BigArray は移動セマンティックをサポートしていませんが、コピー セマンティックのみをサポートしています。行 (2) で BigArray を交換するとどうなりますか?私のスワップ アルゴリズムは、内部でムーブ セマンティック (3) を使用します。試してみましょう。
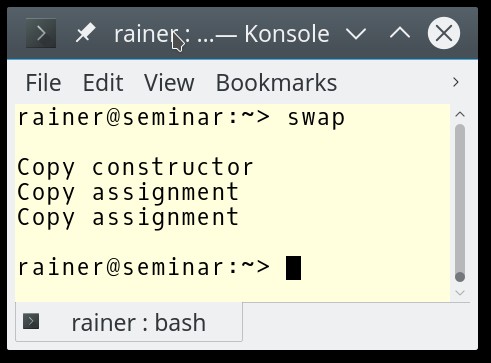
悪いことは何も起こりません。従来のコピー セマンティクスが有効になり、従来の動作が得られます。コピー セマンティックはムーブ セマンティックへの一種のフォールバックです。逆に見ることができます。移動は最適化されたコピーです。
そんなことがあるものか?スワップ アルゴリズムで移動操作を要求しました。その理由は、std::move が右辺値を返すためです。 const 左辺値参照は右辺値にバインドでき、コピー コンストラクターまたはコピー代入演算子は const 左辺値参照を受け取ります。 BigArray が右辺値参照を取るムーブ コンストラクターまたはムーブ代入演算子を持つ場合、両方ともコピー ペンダントよりも優先度が高くなります。
移動セマンティックを使用してアルゴリズムを実装すると、データ型がサポートしている場合、移動セマンティックが自動的に開始されます。そうでない場合は、コピー セマンティックがフォールバックとして使用されます。最悪の場合、古典的な振る舞いになります。
コピー代入演算子にはいくつかの欠陥があると言いました。
BigArray& operator=(const BigArray& other){
if (this != &other){ // (1)
delete [] data;
data = nullptr;
size = other.size;
data = new int[size]; // (2)
std::copy(other.data, other.data + size, data); // (3)
}
return *this;
}
<オール>
スワップ関数を実装することで、これらの欠陥を克服できます。これは、C++ コア ガイドラインで既に提案されています:C.83:値のような型については、noexcept の提供を検討してください。 スワップ機能。これは、非メンバー swap 関数と、swap 関数を使用したコピー代入演算子を持つ新しい BigArray です。
class BigArray{
public:
BigArray(std::size_t sz): size(sz), data(new int[size]){}
BigArray(const BigArray& other): size(other.size), data(new int[other.size]){
std::cout << "Copy constructor" << std::endl;
std::copy(other.data, other.data + size, data);
}
BigArray& operator = (BigArray other){ // (2)
swap(*this, other);
return *this;
}
~BigArray(){
delete[] data;
}
friend void swap(BigArray& first, BigArray& second){ // (1)
std::swap(first.size, second.size);
std::swap(first.data, second.data);
}
private:
std::size_t size;
int* data;
};
swap 関数 inline (1) はメンバーではありません。したがって、呼び出し swap(bigArray1, bigArray2) はそれを使用します。行 (2) のコピー代入演算子の署名は、あなたを驚かせるかもしれません。コピーのため、自己課題テストは必要ありません。さらに、強力な例外保証が保持され、コードの重複はありません。この手法は、コピー アンド スワップ イディオムと呼ばれます。
利用可能な std::swap のオーバーロードされたバージョンが多数あります。 C++ 標準では、約 50 のオーバーロードが提供されています。
Per.10:静的型システムに依存
これは、C++ の一種のメタルールです。コンパイル時にエラーをキャッチします。この重要なトピックについてはすでにいくつかの記事を書いているので、このルールの説明はかなり短くすることができます:
- {} 初期化と組み合わせて auto (自動初期化) による自動型推定を使用すると、多くの利点が得られます。 <オール>
- コンパイラは、auto f =5.0f という正しい型を常に認識しています。
- 型の初期化を忘れることはありません:auto a;動作しません。
- {}-initialization を使用して、縮小変換が開始されないことを確認できます。したがって、自動的に推定される型が期待どおりの型であることを保証できます:int i ={f};コンパイラは、この式で f が int であることをチェックします。そうでない場合は、警告が表示されます。これは中かっこなしでは起こりません:int i =f;.
- コンパイル時に static_assert と type-traits ライブラリの型プロパティをチェックします。チェックが失敗すると、コンパイル時エラーが発生します:static_assert
- ユーザー定義のリテラルと新しい組み込みリテラル (ユーザー定義のリテラル) を使用して、タイプ セーフな演算を行います:auto distancePerWeek=(5 * 120_km + 2 * 1500m - 5 * 400m) / 5;.
- override と final は、仮想メソッドに保証を提供します。コンパイラは、実際に仮想メソッドをオーバーライドしたかどうかを override でチェックします。コンパイラは、final と宣言された仮想メソッドをオーバーライドできないことを final でさらに保証します。
- 新しい Null ポインター定数 nullptr は、C++11 で数値 0 とマクロ NULL の曖昧さを解消します。
次は?
ルールからパフォーマンスまでの旅は続きます。次の投稿では、特に計算を実行時からコンパイル時に移行する方法と、メモリにアクセスする方法について書きます。