パフォーマンスのルールについて書く前に、とても簡単な仕事をします。コンテナの要素に 1 つずつアクセスする。

算数の最後のルールは次のとおりです。
ES.107:unsigned を使用しないでください 添え字の場合は、gsl::index を優先してください
これは簡単な仕事だと言いましたか?正直、これは嘘でした。すべてがうまくいかない可能性があることを確認してください。以下は std::vector の例です。
vector<int> vec = /*...*/; for (int i = 0; i < vec.size(); i += 2) // may not be big enough (2) cout << vec[i] << '\n'; for (unsigned i = 0; i < vec.size(); i += 2) // risk wraparound (3) cout << vec[i] << '\n'; for (auto i = 0; i < vec.size(); i += 2) // may not be big enough (2) cout << vec[i] << '\n'; for (vector<int>::size_type i = 0; i < vec.size(); i += 2) // verbose (1) cout << vec[i] << '\n'; for (auto i = vec.size()-1; i >= 0; i -= 2) // bug (4) cout << vec[i] << '\n'; for (int i = vec.size()-1; i >= 0; i -= 2) // may not be big enough (2) cout << vec[i] << '\n';
怖い?右!行 (1) のみが正しいです。行 (2) で変数 i が小さすぎる場合があります。その結果、オーバーフローが発生する可能性があります。 i は署名されていないため、これは行 (3) には当てはまりません。オーバーフローの代わりに、モジュロ演算が得られます。この素晴らしい効果については、前回の記事「C++ Core Guidelines:Rules to Statements and Arithmetic」で書きました。より具体的には、ES.106 と規定されました。
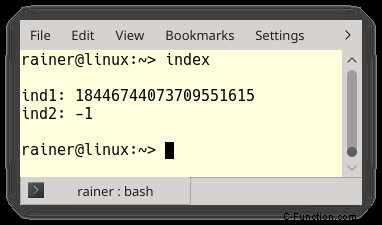
4号線が残っています。これは私のお気に入りです。何が問題ですか?問題は、vec.size() が std::size_t 型であることです。 std::size_t は符号なしの型であるため、負の数を表すことはできません。ベクトルが空の場合に何が起こるか想像してみてください。これは、vec.size() -1 が -1 であることを意味します。その結果、std::size_t 型の最大値が取得されます。
プログラム index.cpp は、この奇妙な動作を示しています。
// index.cpp
#include <iostream>
#include <vector>
int main(){
std::cout << std::endl;
std::vector<int> vec{};
auto ind1 = vec.size() - 1 ;
int ind2 = vec.size() -1 ;
std::cout << "ind1: " << ind1 << std::endl;
std::cout << "ind2: " << ind2 << std::endl;
std::cout << std::endl;
}
出力は次のとおりです。
ガイドラインでは、変数 i は gsl::index 型であることが推奨されています。
for (gsl::index i = 0; i < vec.size(); i += 2) // ok cout << vec[i] << '\n'; for (gsl::index i = vec.size()-1; i >= 0; i -= 2) // ok cout << vec[i] << '\n';
これができない場合は、i に std::vector
パフォーマンスは C++ の領域です。右?したがって、パフォーマンスのルールについて書くことに非常に興味がありました。しかし、ほとんどのルールには牛肉が欠けているため、これはほとんど不可能です。タイトルと理由だけで構成されています。場合によっては、その理由さえも欠落しています。
ともかく。最初のルールは次のとおりです:
- Per.1:理由なく最適化しないでください
- Per.2:時期尚早に最適化しないでください
- Per.3:パフォーマンスが重要でないものは最適化しないでください
- Per.4:単純なコードよりも複雑なコードの方が必ずしも高速であると想定しないでください
- Per.5:低レベル コードが高レベル コードよりも必ずしも高速であると想定しないでください
- Per.6:測定せずにパフォーマンスについて主張しない
一般的なルールに対する一般的なコメントを書く代わりに、これらのルールの例をいくつか示します。ルール Per.4、Per.5、および Per.6 から始めましょう
Per.4:複雑なコードが単純なコードよりも必然的に高速
Per.5:想定しない低レベルのコードは必然的に高レベルのコードよりも高速であること
Per.6:測定せずにパフォーマンスについて主張しない
書き続ける前に免責事項を言わなければなりません:シングルトン パターンの使用はお勧めしません。複雑で低レベルのコードが必ずしもうまくいくとは限らないことを示したいだけです。私の主張を証明するには、パフォーマンスを測定する必要があります.
ずっと前に、シングルトン パターンのスレッド セーフな初期化について、シングルトンのスレッド セーフな初期化について書きました。投稿の重要なアイデアは、4 つのスレッドからシングルトン パターンを 40.000.000 回呼び出し、実行時間を測定することでした。シングルトン パターンは遅延方式で初期化されます。したがって、最初の呼び出しで初期化する必要があります。
さまざまな方法でシングルトン パターンを実装しました。 std::lock_guard と関数 std::call_once を std::once_flag と組み合わせて使用しました。私は静的変数でそれをしました。私はアトミックを使用し、パフォーマンス上の理由からシーケンシャルの一貫性を破りました.
私のポインタを明確にするために。最も簡単な実装と最も難しい実装をお見せしたいと思います.
最も簡単な実装は、いわゆる Meyers シングルトンです。 C++11 標準では、ブロック スコープを持つ静的変数がスレッド セーフな方法で初期化されることが保証されているため、スレッド セーフです。
// singletonMeyers.cpp
#include <chrono>
#include <iostream>
#include <future>
constexpr auto tenMill= 10000000;
class MySingleton{
public:
static MySingleton& getInstance(){
static MySingleton instance; // (1)
// volatile int dummy{};
return instance;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
};
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for (size_t i= 0; i < tenMill; ++i){
MySingleton::getInstance(); // (2)
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
行 (1) は、シングルトンがスレッドセーフな方法で初期化されるという C++11 ランタイムの保証を使用します。メイン関数の 4 つのスレッドのそれぞれが、シングルトン インライン (2) を 1000 万回呼び出します。合計で、これにより 4,000 万回の呼び出しが行われます。
しかし、私はもっとうまくやることができます。今回はアトミックを使用して、シングルトン パターンをスレッド セーフにします。私の実装は、悪名高いダブルチェック ロック パターンに基づいています。簡単にするために、クラス MySingleton の実装のみを示します。
class MySingleton{
public:
static MySingleton* getInstance(){
MySingleton* sin= instance.load(std::memory_order_acquire);
if ( !sin ){
std::lock_guard<std::mutex> myLock(myMutex);
sin= instance.load(std::memory_order_relaxed);
if( !sin ){
sin= new MySingleton();
instance.store(sin,std::memory_order_release);
}
}
// volatile int dummy{};
return sin;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
static std::atomic<MySingleton*> instance;
static std::mutex myMutex;
};
std::atomic<MySingleton*> MySingleton::instance;
std::mutex MySingleton::myMutex;
ダブルチェックのロックパターンが壊れていると聞いたことがあるかもしれません。もちろん、私の実装ではありません!私を信じないなら、私に証明してください。まず、メモリ モデルを検討し、取得と解放のセマンティックについて考え、この実装で保持される同期と順序付けの制約について検討する必要があります。これは簡単な仕事ではありません。しかしご存知のとおり、高度に洗練されたコードは報われます。
くそ。ルール Per.6 を忘れました:Linux での Meyers シングルトンのパフォーマンスの数値は次のとおりです。プログラムを最大限に最適化してコンパイルしました。 Windows での数字は同じ球場にありました。 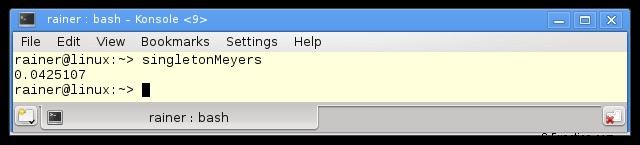
今、私は興味があります。高度に洗練されたコードの数値は?アトミックでどのようなパフォーマンスが得られるか見てみましょう。
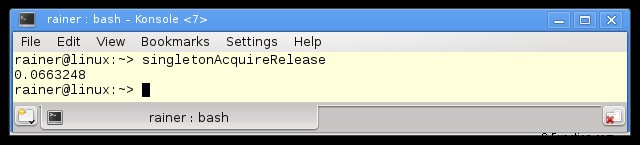
50% パーセント遅い! 50% 遅くなり、実装が正しいかどうかさえわかりません。免責事項:実装は正しいです。
実際、Meyers シングルトンは、シングルトン パターンのスレッド セーフな実装を取得するための最速かつ最も簡単な方法でした。詳細に興味がある場合は、私の投稿を読んでください:シングルトンのスレッドセーフな初期化。
次は?
ガイドラインには、10 を超えるパフォーマンスのルールが残されています。このような一般的な規則について書くのは非常に困難ですが、次の投稿でいくつかのアイデアを念頭に置いています.