アイデアは非常に単純です。標準テンプレート (STL) には、範囲とその要素を検索、カウント、および操作するための 100 を超えるアルゴリズムがあります。 C++17 では、そのうちの 69 個がオーバーロードされ、いくつかの新しいものが追加されています。オーバーロードされた新しいアルゴリズムは、いわゆる実行ポリシーで呼び出すことができます。実行ポリシーを使用することで、アルゴリズムを順次、並列、または並列とベクトル化のいずれで実行するかを指定できます。
前回の投稿は、主にオーバーロードされたアルゴリズムに関するものでした。興味のある方は、標準テンプレート ライブラリの並列アルゴリズムの投稿をお読みください。
今日は、7 つの新しいアルゴリズムについて書きます。
std::for_each_n std::exclusive_scan std::inclusive_scan std::transform_exclusive_scan std::transform_inclusive_scan std::parallel::reduce std::parallel::transform_reduce
std::for_each_n 以外では、これらの名前は非常に珍しいものです。ちょっと寄り道して、Haskell について少し書かせてください。
ちょっと回り道
長い話を短くするために。すべての新しい関数には、純粋な関数型言語 Haskell のペンダントがあります。
- for_each_n は Haskell では map と呼ばれます。
- exclusive_scan と inclusive_scan は、Haskell では scanl と scanl1 と呼ばれます。
- transform_exclusive_scan と transform_inclusive_scan は、Haskell 関数 map と scanl または scanl1 を組み合わせたものです。
- reduce は、Haskell では foldl または foldl1 と呼ばれます。
- transform_reduce は、Haskell 関数 map と foldl または foldl1 を組み合わせたものです。
Haskell の実際の動作をお見せする前に、さまざまな機能について少しお話しさせてください。
- map は関数をリストに適用します。
- foldl と foldl1 は、二項演算をリストに適用し、リストを値に減らします。 foldl は foldl1 とは逆に初期値を必要とします
- scanl と scanl1 は、foldl と foldl1 と同じ戦略を適用しますが、すべて中間値を生成します。これで、リストが返されます。
- foldl、foldl1、scanl、scanl1 は左からジョブを開始します。
次にアクションです。これが Haskell のインタプリタ シェルです。
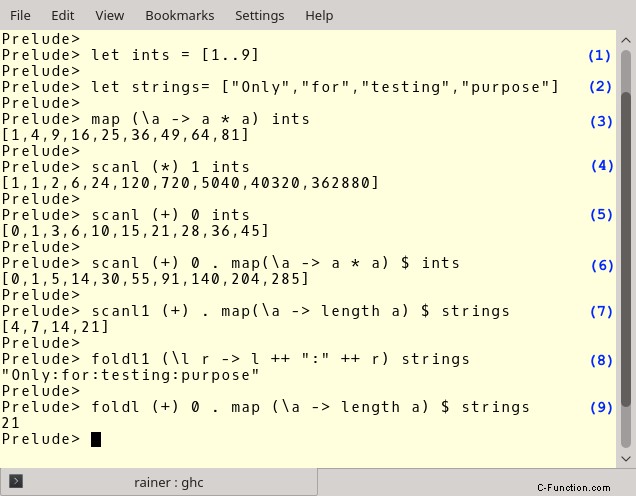
(1) と (2) は、整数のリストと文字列のリストを定義します。 (3) では、ラムダ関数 (\a -> a * a) を int のリストに適用しています。 (4) と (5) はより洗練されたものです。式 (4) は、乗算の中立要素として 1 で始まる整数のすべてのペアを乗算 (*) します。式(5)は加算に相当する。式 (6)、(7)、および (9) は、命令的な目で読むのは非常に困難です。右から左に読む必要があります。 scanl1 (+) . map(\a -> length a (7) は関数合成です。ドット (.) 記号は 2 つの関数を構成します。最初の関数は各要素をその長さにマップし、2 番目の関数は長さのリストを一緒に追加します。(9)は 7 に似ています. 違いは, foldl は 1 つの値を生成し, 初期要素を必要とすることです. これは 0 です. これで, 式 (8) が読めるようになります. この式は 2 つの文字列を連続して ":" 文字で結合します.
なぜ私が C++ のブログに Haskell についてこれほどまでに挑戦的なことを書いているのか、疑問に思っていると思います。それには 2 つの正当な理由があります。最初は、C++ 関数の歴史を知っています。次に、Haskell ペンダントと比較すると、C++ 関数を理解するのがはるかに簡単になります。
それでは、いよいよ C++ から始めましょう。
7 つの新しいアルゴリズム
約束しましたが、少し読みづらくなるかもしれません。
// newAlgorithm.cpp
#include <hpx/hpx_init.hpp>
#include <hpx/hpx.hpp>
#include <hpx/include/parallel_numeric.hpp>
#include <hpx/include/parallel_algorithm.hpp>
#include <hpx/include/iostreams.hpp>
#include <string>
#include <vector>
int hpx_main(){
hpx::cout << hpx::endl;
// for_each_n
std::vector<int> intVec{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; // 1
hpx::parallel::for_each_n(hpx::parallel::execution::par, // 2
intVec.begin(), 5, [](int& arg){ arg *= arg; });
hpx::cout << "for_each_n: ";
for (auto v: intVec) hpx::cout << v << " ";
hpx::cout << "\n\n";
// exclusive_scan and inclusive_scan
std::vector<int> resVec{1, 2, 3, 4, 5, 6, 7, 8, 9};
hpx::parallel::exclusive_scan(hpx::parallel::execution::par, // 3
resVec.begin(), resVec.end(), resVec.begin(), 1,
[](int fir, int sec){ return fir * sec; });
hpx::cout << "exclusive_scan: ";
for (auto v: resVec) hpx::cout << v << " ";
hpx::cout << hpx::endl;
std::vector<int> resVec2{1, 2, 3, 4, 5, 6, 7, 8, 9};
hpx::parallel::inclusive_scan(hpx::parallel::execution::par, // 5
resVec2.begin(), resVec2.end(), resVec2.begin(),
[](int fir, int sec){ return fir * sec; }, 1);
hpx::cout << "inclusive_scan: ";
for (auto v: resVec2) hpx::cout << v << " ";
hpx::cout << "\n\n";
// transform_exclusive_scan and transform_inclusive_scan
std::vector<int> resVec3{1, 2, 3, 4, 5, 6, 7, 8, 9};
std::vector<int> resVec4(resVec3.size());
hpx::parallel::transform_exclusive_scan(hpx::parallel::execution::par, // 6
resVec3.begin(), resVec3.end(),
resVec4.begin(), 0,
[](int fir, int sec){ return fir + sec; },
[](int arg){ return arg *= arg; });
hpx::cout << "transform_exclusive_scan: ";
for (auto v: resVec4) hpx::cout << v << " ";
hpx::cout << hpx::endl;
std::vector<std::string> strVec{"Only","for","testing","purpose"}; // 7
std::vector<int> resVec5(strVec.size());
hpx::parallel::transform_inclusive_scan(hpx::parallel::execution::par, // 8
strVec.begin(), strVec.end(),
resVec5.begin(), 0,
[](auto fir, auto sec){ return fir + sec; },
[](auto s){ return s.length(); });
hpx::cout << "transform_inclusive_scan: ";
for (auto v: resVec5) hpx::cout << v << " ";
hpx::cout << "\n\n";
// reduce and transform_reduce
std::vector<std::string> strVec2{"Only","for","testing","purpose"};
std::string res = hpx::parallel::reduce(hpx::parallel::execution::par, // 9
strVec2.begin() + 1, strVec2.end(), strVec2[0],
[](auto fir, auto sec){ return fir + ":" + sec; });
hpx::cout << "reduce: " << res << hpx::endl;
// 11
std::size_t res7 = hpx::parallel::parallel::transform_reduce(hpx::parallel::execution::par,
strVec2.begin(), strVec2.end(),
[](std::string s){ return s.length(); },
0, [](std::size_t a, std::size_t b){ return a + b; });
hpx::cout << "transform_reduce: " << res7 << hpx::endl;
hpx::cout << hpx::endl;
return hpx::finalize();
}
int main(int argc, char* argv[]){
// By default this should run on all available cores
std::vector<std::string> const cfg = {"hpx.os_threads=all"};
// Initialize and run HPX
return hpx::init(argc, argv, cfg);
}
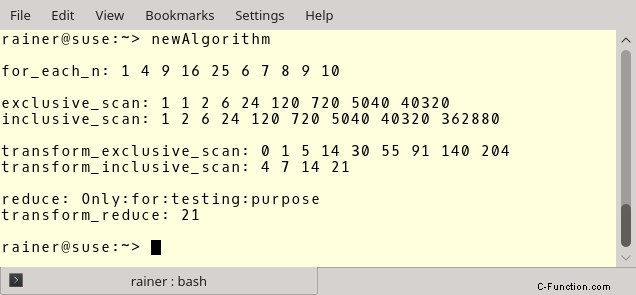
プログラムの出力を示してソース コードを説明する前に、一般的な意見を述べなければなりません。私の知る限り、利用可能な並列 STL の実装はありません。したがって、名前空間 hpx を使用する HPX 実装を使用しました。したがって、名前空間 hpx を std に置き換えて、知っている hpx_main 関数にコードを記述すると、STL アルゴリズムはどのようになるかがわかります。
Haskell に対応して、int (1) と文字列 (7) の std::vector を使用します。
(2) の for_each_n アルゴリズムは、ベクトルの最初の n 個の整数を 2 のべき乗にマップします。
exclusive_scan (3) と inclusive_scan (5) はよく似ています。どちらも要素に二項演算を適用します。違いは、exclusive_scan が各反復で最後の要素を除外することです。ここに、対応する Haskell 式があります:scanl (*) 1 ints.
transform_exclusive_scan (6) は非常に読みにくいです。試してみましょう。最初のステップでラムダ関数 [](int arg){ return arg *=arg; を適用します。 resVec3.begin() から resVec3.end() までの範囲の各要素に。次に、2 番目のステップで二項演算 [](int fir, int sec){ return fir + sec; を適用します。 } を中間ベクトルに。つまり、最初の要素として 0 を使用してすべての要素を合計します。結果は resVec4.begin() に送られます。長い話を短くするために。これが Haskell です:scanl (+) 0 。 map(\a -> a * a) $ ints.
(8) の transform_inclusive_scan 関数も同様です。この関数は、各要素をその長さにマップします。 Haskell でもう一度:scanl1 (+) 。 map(\a -> 長さ a) $ 文字列。
これで、reduce 関数は非常に読みやすくなっているはずです。入力ベクトルの各要素の間に「:」文字を挿入します。結果の文字列は、「:」文字で始まってはなりません。したがって、範囲は 2 番目の要素 (strVec2.begin() + 1) から始まり、最初の要素はベクターの最初の要素 strVec2[0] になります。 Haskell は次のとおりです。 foldl1 (\l r -> l ++ ":" ++ r) 文字列。
(11) の transform_reduce 式を理解したい場合は、標準テンプレート ライブラリの並列アルゴリズムの投稿をお読みください。機能については、もっと言いたいことがあります。せっかちな読者のために。 Haskell の簡潔な式:foldl (+) 0 。マップ (\a -> 長さ a) $ 文字列.
プログラムの出力を調べると役立つはずです。
最後のコメント
7 つの新しいアルゴリズムはそれぞれ異なる種類で存在します。初期要素の有無にかかわらず、実行ポリシーを指定してまたは指定せずに、それらを呼び出すことができます。二項演算子がなくても、std::scan や std::parallel::reduce などの二項演算子を必要とする関数を呼び出すことができます。この場合、追加はデフォルトとして使用されます。アルゴリズムを並列で、または並列でベクトル化して実行するには、二項演算子を連想にする必要があります。アルゴリズムは多くのコアで非常に簡単に実行できるため、これは非常に理にかなっています。詳細については、ウィキペディアの prefix_sum の記事を参照してください。新しいアルゴリズムの詳細:並列処理の拡張。
次は?
すみません、それは長い投稿でした。しかし、そこから 2 つの投稿を作成しても意味がありません。次の投稿では、連想コンテナー (セットとマップ) のパフォーマンスが改善されたインターフェースと、STL コンテナーの統一されたインターフェースについて書きます。