将来についての予測は難しい。特に、C++20 程度の場合です。とはいえ、水晶玉を調べて、C++17 で得られるものと C++20 で期待できるものについて、次の投稿で書きます。
C++11 以降、C++ はマルチコア アーキテクチャの要件に直面しています。 2011 年に公開された標準では、多数のスレッドが存在する場合にプログラムがどのように動作するかが定義されています。 C++11 のマルチスレッド機能は、2 つの部分で構成されています。一方、明確に定義されたメモリ モデルがあります。一方、標準化されたスレッド API があります。
明確に定義されたメモリ モデルは、次の質問に対処します。
<オール>C++11 の標準化されたスレッド インターフェースは、次のコンポーネントで構成されています。
<オール>それほど退屈でない場合は、メモリ モデルと標準化されたスレッド API に関する投稿をお読みください。
マルチスレッドの眼鏡をかけていると、C++14 にはあまり提供するものはありません。 C++14 は、リーダー/ライター ロックを追加しました。
発生する疑問は次のとおりです:C++ の未来は何を提供するのでしょうか?
C++17
C++17 では、標準テンプレート ライブラリのほとんどのアルゴリズムが並列バージョンで利用できるようになります。したがって、いわゆる実行ポリシーを使用してアルゴリズムを呼び出すことができます。この実行ポリシーは、アルゴリズムが順次 (std::seq)、並列 (std::par)、または並列でベクトル化 (std::par_unseq) を実行するかどうかを指定します。
std::vector<int> vec ={3, 2, 1, 4, 5, 6, 10, 8, 9, 4};
std::sort(vec.begin(), vec.end()); // sequential as ever
std::sort(std::execution::seq, vec.begin(), vec.end()); // sequential
std::sort(std::execution::par, vec.begin(), vec.end()); // parallel
std::sort(std::execution::par_unseq, vec.begin(), vec.end()); // parallel and vectorized
したがって、並べ替えアルゴリズムの 1 番目と 2 番目のバリエーションは順次実行され、3 番目は並列に実行され、4 番目は並列に実行されてベクトル化されます。
C++20 は、まったく新しいマルチスレッドの概念を提供します。重要なアイデアは、マルチスレッド化がはるかに単純になり、エラーが発生しにくくなるということです.
C++20
アトミック スマート ポインター
アトミック スマート ポインター std::shared_ptr および std::weak_ptr には、マルチスレッド プログラムで概念上の問題があります。それらは変更可能な状態を共有します。したがって、データ競合が発生しやすく、未定義の動作になります。 std::shared_ptr と std::weak_ptr は、参照カウンターの増分または減分がアトミック操作であり、リソースが 1 回だけ削除されることを保証しますが、そのリソースへのアクセスがアトミックであることはどちらも保証しません。新しいアトミック スマート ポインターは、この問題を解決します。
std::atomic_shared_ptr std::atomic_weak_ptr
promises と futures と呼ばれるタスクにより、C++11 で新しいマルチスレッドの概念が得られました。タスクには多くの機能がありますが、大きな欠点があります。 Future は C++11 では構成できません。
std::future 拡張機能
これは、C++20 の先物には当てはまりません。
- その前身の準備が整う:
次に:
future<int> f1= async([]() {return 123;});
future<string> f2 = f1.then([](future<int> f) {
return f.get().to_string();
});
- 前任者の 1 人が準備完了:
when_any:
future<int> futures[] = {async([]() { return intResult(125); }),
async([]() { return intResult(456); })};
future<vector<future<int>>> any_f = when_any(begin(futures),end(futures));
- すべての前任者の準備が整います:
when_all:
future<int> futures[] = {async([]() { return intResult(125); }),
async([]() { return intResult(456); })};
future<vector<future<int>>> all_f = when_all(begin(futures), end(futures));
C++14 にはセマフォがありません。セマフォは、スレッドが共通リソースへのアクセスを制御できるようにします。問題ありません。C++20 では、ラッチとバリアが得られます。
ラッチとバリア
カウンタがゼロになるまで同期点で待機するために、ラッチとバリアを使用できます。違いは、std::latch は 1 回しか使用できないことです。 std::barrier と std::flex_barrier をもう一度。 std::barrier とは対照的に、std::flex_barrier は反復ごとにカウンターを調整できます。
1 2 3 4 5 6 7 8 9 10 11 12 | void doWork(threadpool* pool){
latch completion_latch(NUMBER_TASKS);
for (int i = 0; i < NUMBER_TASKS; ++i){
pool->add_task([&]{
// perform the work
...
completion_latch.count_down();
});
}
// block until all tasks are done
completion_latch.wait();
}
|
関数 doWork を実行しているスレッドは、11 行目で completion_latch が 0 になるまで待機しています。complete_latch は、2 行目で NUMBER_TASKS に設定され、7 行目でデクリメントされます。
コルーチンは一般化された関数です。関数とは逆に、コルーチンの状態を維持したまま、実行を一時停止および再開できます。
コルーチン
コルーチンは、多くの場合、オペレーティング システム、イベント ループ、無限リスト、またはパイプラインで協調的なマルチタスクを実装するための手段として選択されます。
1 2 3 4 5 6 7 8 9 10 | generator<int> getInts(int first, int last){
for (auto i= first; i <= last; ++i){
co_yield i;
}
}
int main(){
for (auto i: getInts(5, 10)){
std::cout << i << " "; // 5 6 7 8 9 10
}
|
関数 getInts (1 行目から 5 行目) は、要求に応じて値を返すジェネレーターを返します。式 co_yield には 2 つの目的があります。最初に新しい値を返し、次に新しい値が要求されるまで待機します。範囲ベースの for ループは、5 から 10 までの値を連続して要求します。
トランザクション メモリにより、確立されたトランザクションの考え方がソフトウェアに適用されます。
トランザクション メモリ
トランザクション メモリのアイデアは、データベース理論のトランザクションに基づいています。トランザクションは、プロパティ A を提供するアクションです トミシティ、C 一貫性、私 孤独と D 耐久性(ACID)。永続性を除いて、すべてのプロパティは C++ のトランザクション メモリに保持されます。 C++ には、2 つの種類のトランザクション メモリがあります。 1 つは同期ブロックと呼ばれ、もう 1 つはアトミック ブロックと呼ばれます。どちらも全体的な順序で実行され、グローバル ロックによって保護されているかのように動作するという共通点があります。同期ブロックとは対照的に、アトミック ブロックはトランザクションに安全でないコードを実行できません。
したがって、同期ブロックでは std::cout を呼び出すことができますが、atomic ブロックでは呼び出すことができません。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | int func() {
static int i = 0;
synchronized{
std::cout << "Not interleaved \n";
++i;
return i;
}
}
int main(){
std::vector<std::thread> v(10);
for(auto& t: v)
t = std::thread([]{ for(int n = 0; n < 10; ++n) func(); });
}
|
3 行目の synchronized キーワードは、同期ブロック (3 ~ 7 行目) の実行が重複しないことを保証します。これは特に、すべての同期ブロック間に 1 つの完全な順序があることを意味します。逆に言うと。各同期ブロックの終了は、次の同期ブロックの開始と同期します。
私はこの投稿を C++17 および C++20 でのマルチスレッド化と呼びましたが、C++ では、並列 STL のほかにタスク ブロックを使用してより多くの並列機能を利用できます。
タスク ブロック
タスク ブロックは fork-join パラダイムを実装します。グラフィックは重要なアイデアを示しています。
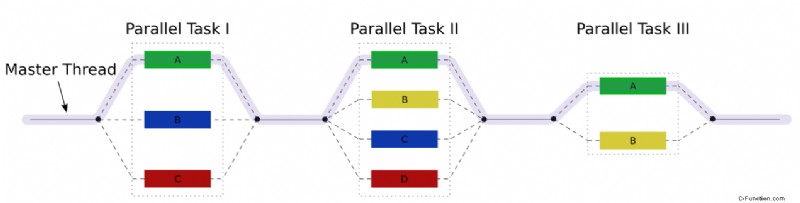
タスク ブロックで run を使用すると、タスク ブロックの最後に結合される新しいタスクをフォークできます。
1 2 3 4 5 6 7 8 9 10 11 | template <typename Func>
int traverse(node& n, Func && f){
int left = 0, right = 0;
define_task_block(
[&](task_block& tb){
if (n.left) tb.run([&]{ left = traverse(*n.left, f); });
if (n.right) tb.run([&]{ right = traverse(*n.right, f); });
}
);
return f(n) + left + right;
} |
traverse は、ツリーの各ノードで関数 Func を呼び出す関数テンプレートです。式 define_task_block は、タスク ブロックを定義します。この領域には、新しいタスクを開始するためのタスク ブロック tb があります。まさにそれが、ツリーの左右の分岐で発生しています (6 行目と 7 行目)。行 9 はタスク ブロックの終わりであり、したがって同期ポイントです。
次は?
C++17 と C++20 の新しいマルチスレッド機能の概要を説明した後、次の投稿で詳細を説明します。並列 STL から始めます。私の投稿には、答えよりも多くの疑問が残されているに違いありません。