セマンティクスをコピーするための移動セマンティクスの利点については、多くのことが書かれています。コストのかかるコピー操作の代わりに、安価な移動操作を使用できます。しかし、それはどういう意味ですか?この投稿では、標準テンプレート ライブラリ (STL) のコンテナーのコピーおよび移動セマンティックのパフォーマンスを比較します。
番号を表示する前に、背景情報を少し説明します。
コピーと移動のセマンティクス
微妙な違いは、コピー セマンティックまたはムーブ セマンティックを使用して既存のオブジェクトに基づいて新しいオブジェクトを作成する場合、コピー セマンティックはリソースの要素をコピーし、ムーブ セマンティックはリソースの要素を移動することです。もちろん、コピーは高く、移動は安い。しかし、追加の重大な結果があります。
<オール>2 番目の点は、std::string で示すのに非常に適しています。
まず、古典的なコピー セマンティクス。
コピー セマンティクス
std::string1("ABCDEF");
std::string str2;
str2 = str1;
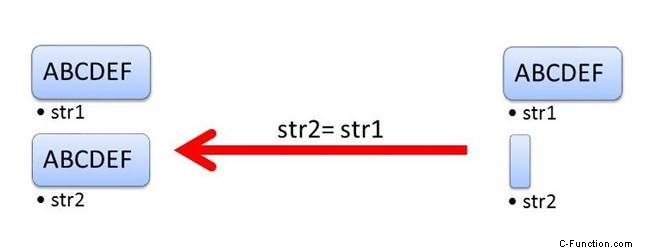
文字列 str1 と str2 は両方とも、コピー操作の後、同じ内容 "ABCDEF" を持っています。では、移動セマンティクスの違いは何ですか。
ムーブ セマンティクス
std::string1("ABCDEF");
std::string str3;
str3 = std::move(str1);

文字列 str1 は、空の "" の後のコピー セマンティックに反します。これは保証されていませんが、多くの場合そうです。関数 std::move を使用して移動セマンティックを明示的に要求しました。移動セマンティックのソースが不要であることが確実な場合、コンパイラは自動的に移動セマンティックを実行します。
std::move を使用して、プログラム内で移動セマンティックを明示的に要求します。
パフォーマンスの違い
STL コンテナーのコピー セマンティックとムーブ セマンティックのパフォーマンスの違いは何ですか。私の比較には std::string が含まれます。より多くの等しいキーを持つことができる連想コンテナーは無視します。特に、コンテナーのコピー セマンティックとムーブ セマンティックのパフォーマンス比に関心があります。
境界条件
最大限の最適化を行ったプログラムと最適化を行わなかったプログラムの違いはそれほど劇的ではありませんでした。したがって、簡単にするために、最大限の最適化を行った実行可能プログラムの結果のみを提供します。私は、GCC 4.9.2 コンパイラーと、Microsoft Visual Studio 2015 の一部である cl.exe コンパイラーを使用しています。どちらのプラットフォームも 64 ビットです。したがって、実行可能ファイルは 64 ビット用にビルドされます。
プログラム
STLにはたくさんのコンテナがあります。そのため、プログラムは少し長くなります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | // movePerformance.cpp
#include <array>
#include <forward_list>
#include <chrono>
#include <deque>
#include <iomanip>
#include <iostream>
#include <list>
#include <map>
#include <numeric>
#include <set>
#include <string>
#include <unordered_map>
#include <unordered_set>
#include <utility>
#include <vector>
const int SIZE = 10000000;
template <typename T>
void measurePerformance(T& t, const std::string& cont){
std::cout << std::fixed << std::setprecision(10);
auto begin= std::chrono::system_clock::now();
T t1(t);
auto last= std::chrono::system_clock::now() - begin;
std::cout << cont << std::endl;
auto copyTime= std::chrono::duration<double>(last).count();
std::cout << " Copy: " << copyTime << " sec" << std::endl;
begin= std::chrono::system_clock::now();
T t2(std::move(t));
last= std::chrono::system_clock::now() - begin;
auto moveTime= std::chrono::duration<double>(last).count();
std::cout << " Move: " << moveTime << " sec" << std::endl;
std::cout << std::setprecision(2);
std::cout << " Ratio (copy time/move time): " << (copyTime/moveTime) << std::endl;
std::cout << std::endl;
}
int main(){
std::cout << std::endl;
{
std::array<int,SIZE/1000> myArray;
measurePerformance(myArray,"std::array<int,SIZE/1000>");
}
{
std::vector<int> myVec(SIZE);
measurePerformance(myVec,"std::vector<int>(SIZE)");
}
{
std::deque<int>myDec(SIZE);
measurePerformance(myDec,"std::deque<int>(SIZE)");
}
{
std::list<int>myList(SIZE);
measurePerformance(myList,"std::list<int>(SIZE)");
}
{
std::forward_list<int>myForwardList(SIZE);
measurePerformance(myForwardList,"std::forward_list<int>(SIZE)");
}
{
std::string myString(SIZE,' ');
measurePerformance(myString,"std::string(SIZE,' ')");
}
std::vector<int> tmpVec(SIZE);
std::iota(tmpVec.begin(),tmpVec.end(),0);
{
std::set<int>mySet(tmpVec.begin(),tmpVec.end());
measurePerformance(mySet,"std::set<int>");
}
{
std::unordered_set<int>myUnorderedSet(tmpVec.begin(),tmpVec.end());
measurePerformance(myUnorderedSet,"std::unordered_set<int>");
}
{
std::map<int,int>myMap;
for (auto i= 0; i <= SIZE; ++i) myMap[i]= i;
measurePerformance(myMap,"std::map<int,int>");
}
{
std::unordered_map<int,int>myUnorderedMap;
for (auto i= 0; i <= SIZE; ++i) myUnorderedMap[i]= i;
measurePerformance(myUnorderedMap,"std::unordered_map<int,int>");
}
}
|
このプログラムの考え方は、コンテナーを 1000 万の要素で初期化することです。もちろん、初期化はコピーと移動のセマンティックで行われます。パフォーマンス測定は関数テンプレート measurePerformane で行われます (21 ~ 44 行目)。この関数は、コンテナーとコンテナーの名前を引数として取ります。 Chrono ライブラリのおかげで、コピーの初期化 (27 行目) と移動の初期化 (34 行目) にかかる時間を測定できます。最後に、コピー セマンティックとムーブ セマンティックの比率に関心があります (40 行目)。
メイン関数で何が起こっていますか?コンテナごとに独自のスコープを作成して、自動的に解放されるようにします。したがって、myArray (51 行目) は自動的に解放され、そのスコープは終了します (53 行目)。コンテナは非常に大きいため、メモリを解放する必要があります。各コンテナーには 1000 万の要素があると主張しました。それは myArray には当てはまりません。 myArray はヒープに割り当てられないため、そのサイズを大幅に縮小する必要があります。しかし今、残りのコンテナに。 std::vector、std::deque、std::list、および std::forward_list では、55 行目から 73 行目に残りの順次コンテナーがあります。 75 ~ 78 行目に std::string が続きます。残りは連想コンテナです。連想コンテナーの 1 つの特徴に注意を払う必要があります。一意のキー、つまりサイズが 1000 万になるように、0 から 9999999 までの数字をキーとして使用します。関数 std::iota がその役割を果たします。
数字
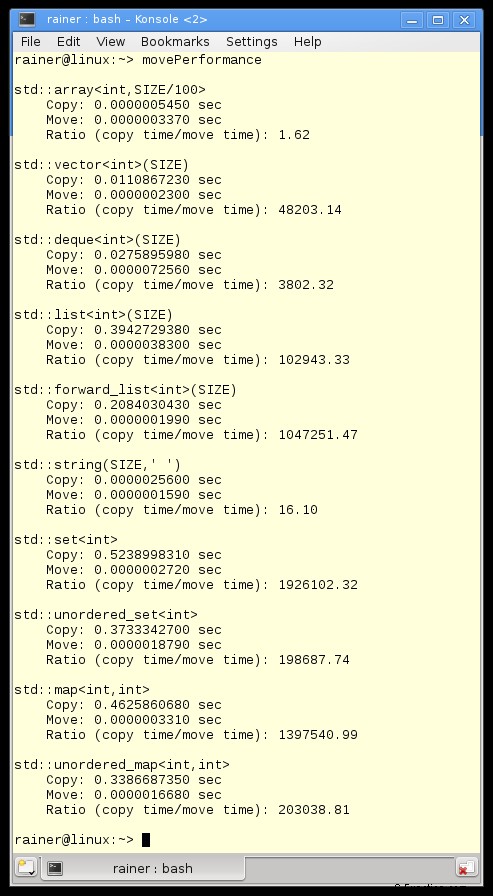
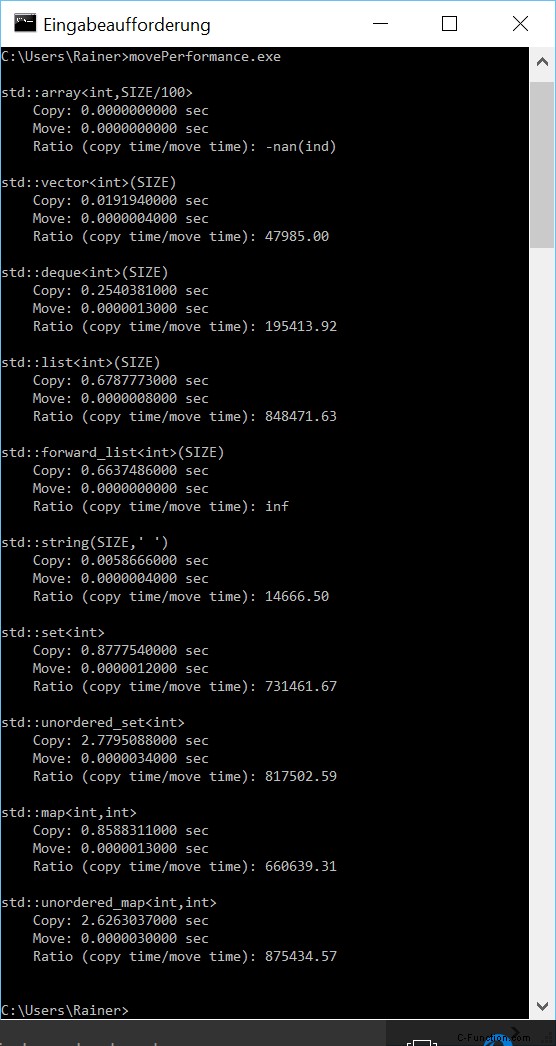
std::array の結果はあまり意味がありません。一方では、std::array はそれほど大きくありません。一方、Windows の時差はクロック std::system_clock では測定できません。
数字からどのような洞察を得ることができますか?
- シーケンシャル コンテナ :std::vector は、予想どおり、コピーまたは移動の場合の最速のコンテナーです。
- シーケンシャル コンテナと連想コンテナ :Linux と Windows でのシーケンシャル コンテナーのコピーが高速になりました。
- コピーと移動のセマンティック :コピー セマンティックとムーブ セマンティックの違いは非常に大きいです。これは特に、連想コンテナに当てはまります。
- std::string :Linux で std::string が奇妙な動作をします。一方では、コピーは非常に高速です。一方、移動はコピーよりも 16 倍高速です。最適化せずにプログラムをコンパイルして実行すると、さらに奇妙になります。 Linux では、移動セマンティックはコピー セマンティックよりも 1.5 倍高速であるという結果が得られます。しかし、これらの数値は、Windows の数値とは大きく矛盾しています。 Windows では、移動セマンティックはコピー セマンティックよりも 15000 倍高速です。
std::string に関するなぞなぞ
Linux と Windows でのコピーと移動のセマンティックのパフォーマンスの違いについて簡単に説明します。私のGCCは、コピーオンライト(牛)に従ってstd::stringを実装しています。これは C++11 標準に準拠していません。ただし、cl.exe は C++11 標準に従って std::string を実装します。プログラムを GCC 6.1 でコンパイルして C++11 を有効にすると、異なる数値が得られます。 GCC の std::string 実装は、5.1 以降 C++11 標準に準拠しています。
以下は、en.cppreference.com のオンライン コンパイラの数値です。
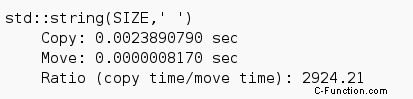
ここで、コピー セマンティックとムーブ セマンティックの間には大きな違いがあります。
次は?
それが移動セマンティクスの動機であったことを願っています。次の投稿では、ムーブ セマンティックの優れた特徴を 2 つ取り上げます。