前回の投稿で std::shared_ptr の全体像を描いた後、この投稿ではこのスマート ポインターの 2 つの特別な側面を紹介したいと思います。まず、std::shared_from_this を使用して、オブジェクトから std::shared_ptr を作成する方法を示します。第二に、私は答えへの質問に興味があります:関数は、コピーまたは参照によって std::shared_ptr を取るべきですか?数字は非常に興味深いものです。
std::shared_ptr from this
std::enable_shared_from_this のおかげで、this から std::shared_ptr を返すオブジェクトを作成できます。したがって、オブジェクトのクラスは、std::enable_shared_from_this から派生した public でなければなりません。これで、メソッド shared_from_this が利用可能になりました。これを使用して、this から std::shared_ptr を作成できます。
プログラムは実際の理論を示しています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | // enableShared.cpp
#include <iostream>
#include <memory>
class ShareMe: public std::enable_shared_from_this<ShareMe>{
public:
std::shared_ptr<ShareMe> getShared(){
return shared_from_this();
}
};
int main(){
std::cout << std::endl;
std::shared_ptr<ShareMe> shareMe(new ShareMe);
std::shared_ptr<ShareMe> shareMe1= shareMe->getShared();
{
auto shareMe2(shareMe1);
std::cout << "shareMe.use_count(): " << shareMe.use_count() << std::endl;
}
std::cout << "shareMe.use_count(): " << shareMe.use_count() << std::endl;
shareMe1.reset();
std::cout << "shareMe.use_count(): " << shareMe.use_count() << std::endl;
std::cout << std::endl;
}
|
スマート ポインター shareMe (17 行目) と、shareMe1 (18 行目) と shareMe2 (20 行目) のコピーは、まったく同じリソースを参照し、参照カウンターをインクリメントおよびデクリメントします。
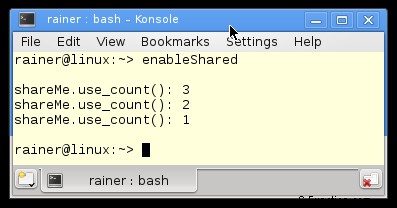
18 行目の shareMe->getShared() の呼び出しは、新しいスマート ポインターを作成します。 getShared() は内部的に (9 行目) 関数 shared_from_this を使用します。
クラス ShareMe には非常に特別なものがあります。
奇妙な繰り返しテンプレート パターン
ShareMe は、基本クラス std::enabled_shared_from_this の派生クラスおよび型引数 (6 行目) です。このパターンは CRTP という造語で、C の略です。 妙にR 繰り返し T テンプレート P アターン。基本クラスのメソッドは呼び出されたときにインスタンス化されるため、明らかに再帰はありません。 CRTP は、静的ポリモーフィズムを実装するために C++ でよく使用されるイディオムです。実行時の仮想メソッドによる動的ポリモーフィズムとは対照的に、静的ポリモーフィズムはコンパイル時に行われます。
しかしここで、std::shared_ptr に戻ります。
関数引数としての std::shared_ptr
したがって、私たちは非常に興味深い質問を扱っています。関数はその std::shared_ptr を参照によってコピーする必要がありますか?でもまず。なぜあなたは気にする必要がありますか?関数がその std::shared_ptr をコピーまたは参照で取得するかどうかは重要ですか?ボンネットの下では、すべてが参照です。私の明確な答えはイエスです。意味的には、違いはありません。パフォーマンスの観点からすると、違いが生じます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | // refVersusCopySharedPtr.cpp
#include <memory>
#include <iostream>
void byReference(std::shared_ptr<int>& refPtr){
std::cout << "refPtr.use_count(): " << refPtr.use_count() << std::endl;
}
void byCopy(std::shared_ptr<int> cpyPtr){
std::cout << "cpyPtr.use_count(): " << cpyPtr.use_count() << std::endl;
}
int main(){
std::cout << std::endl;
auto shrPtr= std::make_shared<int>(2011);
std::cout << "shrPtr.use_count(): " << shrPtr.use_count() << std::endl;
byReference(shrPtr);
byCopy(shrPtr);
std::cout << "shrPtr.use_count(): " << shrPtr.use_count() << std::endl;
std::cout << std::endl;
}
|
関数 byReference (6 行目から 8 行目) と byCopy (10 行目から 12 行目) は、 std::shared_ptr を参照とコピーで取得します。プログラムの出力は重要なポイントを強調しています。
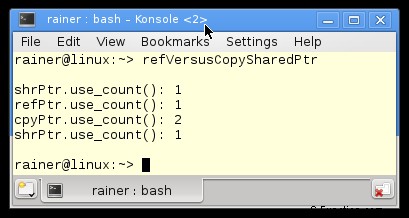
関数 byCopy はその std::shared_ptr をコピーで取得します。したがって、参照カウントは関数本体で 2 に増加し、その後 1 に減少します。問題は今です。参照カウンターのインクリメントとデクリメントのコストはどれくらいですか?参照カウンターのインクリメントはアトミック操作であるため、測定可能な違いが予想されます。正確には。参照カウンターのインクリメントは、セマンティクスが緩和されたアトミック操作です。取得-解放セマンティクスによるアトミック操作のデクリメント。
数字を見てみましょう。
パフォーマンス比較
私の Linux PC が Windows PC よりも強力であることを、パフォーマンスの比較でどのように知ることができますか。したがって、一粒の塩で絶対数を読み取る必要があります。私は GCC 4.8 と Microsoft Visual Studio 15 を使用しています。さらに、プログラムを最適化せずに最大限に翻訳します。最初は、私の小さなテスト プログラムです。
テスト プログラムでは、参照とコピーによって std::shared_ptr を渡し、std::shared_ptr を使用して別の std::shared_ptr を初期化します。これは、オプティマイザーを欺く最も単純なシナリオでした。各関数を 1 億回呼び出します。
プログラム
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | // performanceRefCopyShared.cpp
#include <chrono>
#include <memory>
#include <iostream>
constexpr long long mill= 100000000;
void byReference(std::shared_ptr<int>& refPtr){
volatile auto tmpPtr(refPtr);
}
void byCopy(std::shared_ptr<int> cpyPtr){
volatile auto tmpPtr(cpyPtr);
}
int main(){
std::cout << std::endl;
auto shrPtr= std::make_shared<int>(2011);
auto start = std::chrono::steady_clock::now();
for (long long i= 0; i <= mill; ++i) byReference(shrPtr);
std::chrono::duration<double> dur= std::chrono::steady_clock::now() - start;
std::cout << "by reference: " << dur.count() << " seconds" << std::endl;
start = std::chrono::steady_clock::now();
for (long long i= 0; i<= mill; ++i){
byCopy(shrPtr);
}
dur= std::chrono::steady_clock::now() - start;
std::cout << "by copy: " << dur.count() << " seconds" << std::endl;
std::cout << std::endl;
}
|
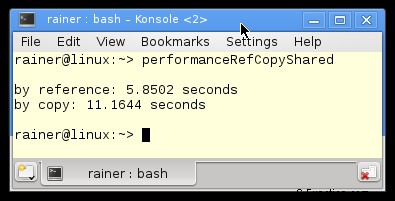
まず、最適化なしのプログラム。
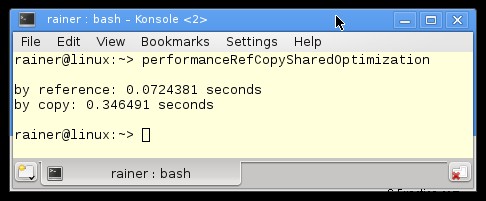
最適化なし
そして今、最大限に最適化されたものです。
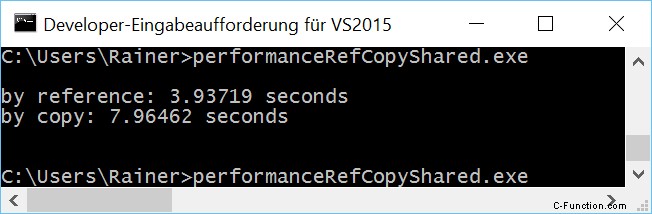
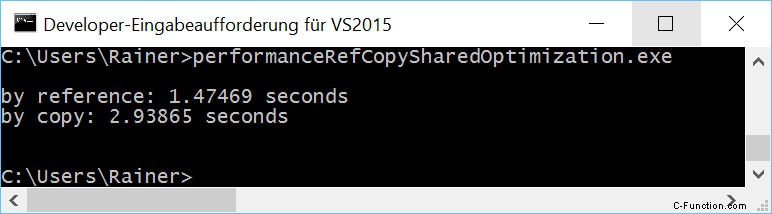
最大限に最適化
私の結論
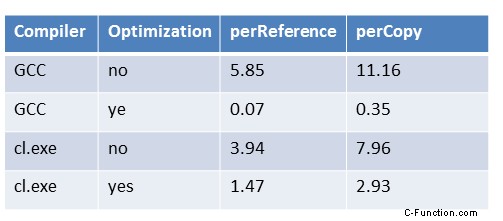
プログラム performanceCopyShared.cpp の生の数値は、明確なメッセージを語っています。
- perReference 関数は、そのペンダント perCopy よりも約 2 倍高速です。 Linux で最大の最適化を行うと、約 5 倍速くなります。
- 最大限に最適化すると、Windows のパフォーマンスが 3 倍向上します。 Linux では 30 ~ 80 倍。
- Windows アプリケーションは、最適化なしでは Linux アプリケーションよりも高速です。私の Windows PC は遅いので、これは興味深いです。
次は?
参照カウントを使用するスマート ポインターの従来の問題は、循環参照を持つことです。したがって、 std::weak_ptr が助けになります。次の投稿では、std::weak_ptr を詳しく見て、循環参照を解除する方法を示します。