注意深く見ると、型特性には大きな最適化の可能性があることがわかります。型特性は、最初のステップでコンパイル時にコードを分析し、2 番目のステップでその分析に基づいてコードを最適化します。そんなことがあるものか?変数のタイプに応じて、アルゴリズムのより高速なバリアントが選択されます。
メモリ領域全体で作業
この考え方は非常に単純で、標準テンプレート ライブラリ (STL) の現在の実装で使用されています。コンテナの要素が単純であれば、std::copy、std::fill、std::equal などの STL のアルゴリズムがメモリ領域に直接適用されます。 std::copy を使用して要素を 1 つずつコピーする代わりに、すべてが 1 つの大きなステップで行われます。内部的には、memcmp、memset、memcpy、memmove などの C 関数が使用されます。 memcpy と memmove の小さな違いは、memmove が重複するメモリ領域を処理できることです。
アルゴリズム std::copy、std::fill、または std::equal の実装は単純な戦略を使用します。 std::copy はラッパーのようなものです。このラッパーは、要素が十分に単純かどうかをチェックします。その場合、ラッパーは作業を最適化されたコピー機能に委任します。そうでない場合は、一般的なコピー アルゴリズムが使用されます。これは、各要素を次々にコピーします。正しい決定を下すために、要素が十分に単純であれば、型特性ライブラリの関数が使用されます。
グラフィックはこの戦略をもう一度示しています:
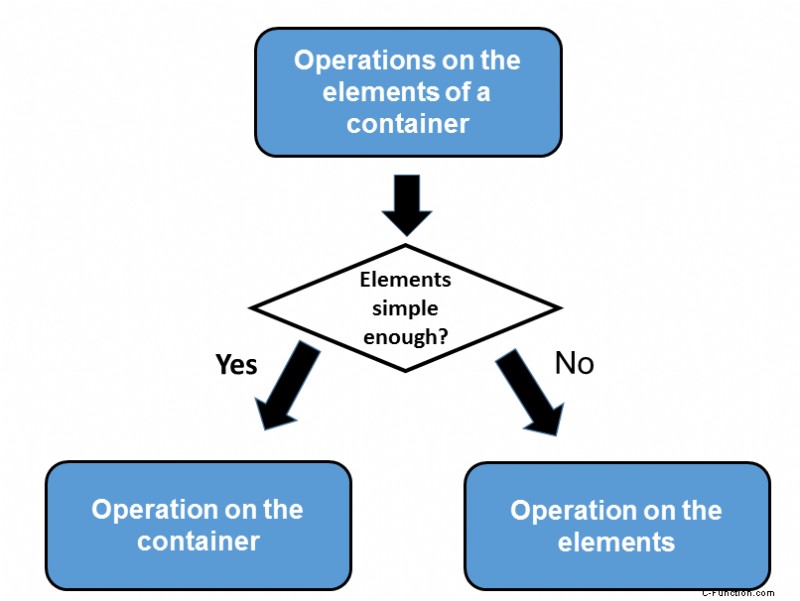
それが理論でしたが、ここに実践があります。 std::fill で使用される戦略はどれですか?
std::fill
std::fill は、範囲内の各要素に値を割り当てます。このリストは簡単な実装を示しています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | // fill.cpp
#include <cstring>
#include <chrono>
#include <iostream>
#include <type_traits>
namespace my{
template <typename I, typename T, bool b>
void fill_impl(I first, I last, const T& val, const std::integral_constant<bool, b>&){
while(first != last){
*first = val;
++first;
}
}
template <typename T>
void fill_impl(T* first, T* last, const T& val, const std::true_type&){
std::memset(first, val, last-first);
}
template <class I, class T>
inline void fill(I first, I last, const T& val){
// typedef std::integral_constant<bool,std::has_trivial_copy_assign<T>::value && (sizeof(T) == 1)> boolType;
typedef std::integral_constant<bool,std::is_trivially_copy_assignable<T>::value && (sizeof(T) == 1)> boolType;
fill_impl(first, last, val, boolType());
}
}
const int arraySize = 100000000;
char charArray1[arraySize]= {0,};
char charArray2[arraySize]= {0,};
int main(){
std::cout << std::endl;
auto begin= std::chrono::system_clock::now();
my::fill(charArray1, charArray1 + arraySize,1);
auto last= std::chrono::system_clock::now() - begin;
std::cout << "charArray1: " << std::chrono::duration<double>(last).count() << " seconds" << std::endl;
begin= std::chrono::system_clock::now();
my::fill(charArray2, charArray2 + arraySize, static_cast<char>(1));
last= std::chrono::system_clock::now() - begin;
std::cout << "charArray2: " << std::chrono::duration<double>(last).count() << " seconds" << std::endl;
std::cout << std::endl;
}
|
my::fill 27 行目で、my::fill_impl のどの実装を適用するかを決定します。最-特徴。投稿で説明します 型をチェックする 型特性関数の背後にある魔法.
私の GCC 4.8 は、関数 std::is_trivially_copy_assignable std::has_trivial_copy_assign の代わりに呼び出します。キーワード default を使用してコンパイラにコピー代入演算子を要求すると、演算子は自明になります。
struct TrivCopyAssign{
TrivCopyAssign& operator=(const TrivCopyAssign& other)= default;
};
コード例に戻ります。 27 行目の boolType() 式が true の場合、18 ~ 21 行目の my::fill_impl の最適化されたバージョンが使用されます。このバリアントは、一般的なバリアント my::fill_impl (行 10 -16) とは反対に、1 億のエントリからなるメモリ領域全体を値 1 で埋めます。sizeof(char) は 1 です。
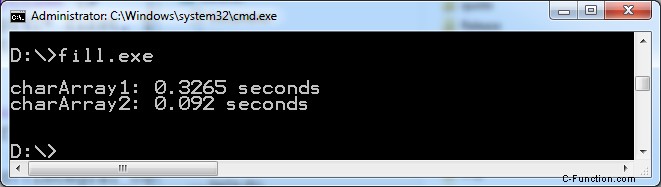
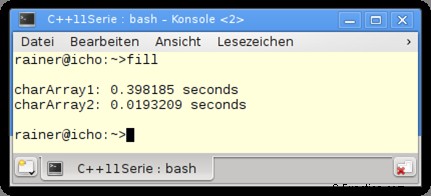
プログラムのパフォーマンスについて教えてください。最適化せずにプログラムをコンパイルしました。最適化されたバリアントの実行は、Windows では約 3 倍高速です。 Linux では約 20 倍高速です。
Microsoft Visual 15
GCC 4.8
アルゴリズムのどのバリアントを使用するかを決定するのは、それほど簡単ではない場合があります.
std::equal
std::equal の実装者は、決定基準を __simple と呼んだため、特別なユーモアを持っていました。コードは GCC 4.8 STL 実装からコピーされます。
1 2 3 4 5 6 7 8 9 10 11 12 | template<typename _II1, typename _II2>
inline bool __equal_aux(_II1 __first1, _II1 __last1, _II2 __first2){
typedef typename iterator_traits<_II1>::value_type _ValueType1;
typedef typename iterator_traits<_II2>::value_type _ValueType2;
const bool __simple = ((__is_integer<_ValueType1>::__value
|| __is_pointer<_ValueType1>::__value )
&& __is_pointer<_II1>::__value
&& __is_pointer<_II2>::__value
&&__are_same<_ValueType1, _ValueType2>::__value
);
return std::__equal<__simple>::equal(__first1, __last1, __first2);
}
|
私は __simple に対して別の認識を持っています。 std::equal の最適化されたバリアントを使用するには、コンテナー要素がいくつかの保証を満たさなければなりません。コンテナーの要素は同じ型 (9 行目) である必要があり、整数またはポインター (5 行目と 6 行目) である必要があります。さらに、反復子はポインターでなければなりません (7 行目と 8 行目)。
次は?
彼らは C++98 標準では実現しませんでした。しかし、C++11 にはハッシュ テーブルがあります。正式名称は順不同の連想コンテナです。非公式には、それらはしばしば辞書と呼ばれます。彼らは、パフォーマンスという 1 つの重要な機能を約束しています。最適なケースではアクセス時間が一定であるためです。
なぜ順不同の連想コンテナが必要なのですか? C++98 の順序付けられた関連コンテナー (std::map、std::set、std::multimap、および std::multiset) との違いは何ですか?それは次の投稿の話です。