acquire-releae セマンティックを使用すると、順次の一貫性が失われます。取得と解放のセマンティックでは、同期はスレッド間ではなく、同じアトミック上のアトミック操作間で行われます。
Acquire-release セマンティック
同期はアトミック操作間でのみ行われるため、取得と解放のセマンティックはより軽量であり、したがって順次整合性よりも高速です。ただし、知的な課題は増えますが。
37 | 45 |
一見すると、すべての操作がアトミックであることがわかります。そのため、プログラムは適切に定義されています。しかし、もう一度見ると、さらに多くのことがわかります。 y のアトミック操作には、フラグ std::memory_order_release (12 行目) と std::memory_order_acquire (16 行目) が関連付けられています。それとは反対に、x のアトミック操作には std::memory_order_relaxed の注釈が付けられます。したがって、x には同期と順序の制約はありません。 x と y の可能な値のキーは、y によってのみ回答できます。
以下を保持します:
<オール>この 3 つのステートメントについて、もう少し詳しく説明します。重要なアイデアは、行 10 の y のストアが行 16 の y のロードと同期するということです。その理由は、操作が同じアトミックで行われ、取得と解放のセマンティックに従うためです。したがって、y は 12 行目で std::memory_order_release を使用し、16 行目で std::memory_order_acquire を使用します。しかし、y に対するペアワイズ演算には、別の非常に興味深い特性があります。それらは y に対して一種のバリアを確立します。そのため、x.store(2000,std::memory_order_relaxed) は 後 に実行できません y.store(std::memory_order_release) であるため、x.load() は 前 に実行できません y.load()。
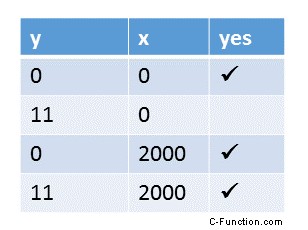
その推論は、逐次一貫性の場合よりも取得と解放のセマンティックの場合の方がより洗練されていました。ただし、x と y の可能な値は同じです。 y ==11 と x ==0 の組み合わせのみは不可能です。
可能なスレッドの 3 つの異なるインターリーブがあり、値 x と y の 3 つの異なる組み合わせで生成されます。
<オール>
最後にテーブル。
CppMem
最初に、CppMem を使用してプログラムをもう一度実行します。
54
(y=11, x=0) 以外のすべての結果が可能であることは既にわかっています。
可能な実行
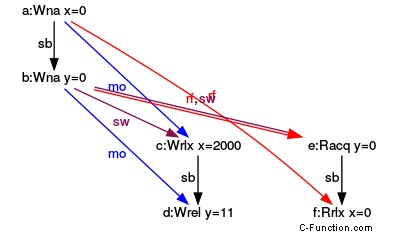
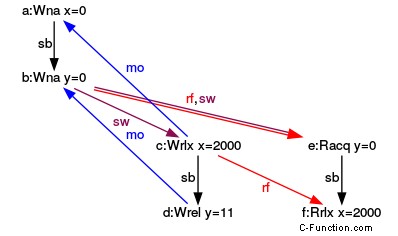
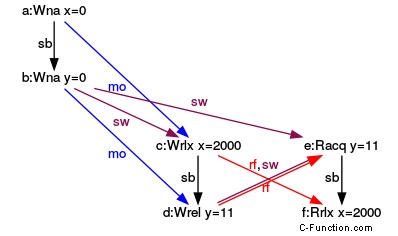
一貫した実行で、3 つのグラフを見てください。グラフは、y のストア - リリースと y からのロード - 取得の間に取得 - リリース セマンティックがあることを示しています。 y (rf ) は、メイン スレッドまたは別のスレッドで発生します。グラフは、sw 矢印で同期との関係を示しています。
(y=0, x=0) の実行
(y=0, x=2000) の実行
(y=11, x=2000) の実行
次は?
しかし、もっとうまくやることができます。なぜ x は原子でなければならないのですか?理由はありません。それは私の最初の、しかし間違った仮定でした。なんで?次の投稿でお読みください。