取得と解放のフェンスは、取得と解放のセマンティックを持つアトミックと同様の同期と順序付けの制約を保証します。違いは細部にあるため、同様です。
メモリ バリアの取得と解放 (フェンス) と、取得と解放のセマンティックを使用するアトミックとの最も明白な違いは、メモリ バリアはアトミックに対する操作を必要としないことです。しかし、もっと微妙な違いがあります。メモリ バリアの取得と解放は、より重いものです。
アトミック操作とメモリ バリア
私の作業を簡単にするために、取得セマンティックでメモリバリアまたはアトミック操作を使用する場合、取得操作について簡単に説明します。同じことが解放操作にも当てはまります。
取得操作と解放操作の重要な考え方は、スレッド間の同期と順序付けの制約を確立することです。これは、緩和されたセマンティック操作または非アトミック操作によるアトミック操作にも当てはまります。ご覧のとおり、取得操作と解放操作はペアで行われます。さらに、取得と解放の意味を持つアトミック変数の操作では、これらが同じアトミック変数に作用することを保持する必要があります。最初のステップでは、これらの操作を個別に見ていきます.
取得操作から始めます。
取得操作
std::memory_order_acquire でアタッチされたアトミック変数に対する読み取り操作は、取得操作です。

それとは反対に、セマンティックを取得する std::atomic_thread_fence があります。

この比較は 2 つの点を強調しています。
<オール>同様のステートメントがリリース メモリ バリアにも当てはまります。
解放操作
メモリ モデル std::memory_order_release にアタッチされたアトミック変数に対する書き込み操作は解放操作です。

さらにメモリバリアを解放します。

アトミック変数 var のリリース操作に加えて、リリース バリアは次の 2 つのポイントを保証します。
<オール>メモリ バリアの簡単な概要が必要な場合は、このブログの最後の投稿をお読みください。しかしここで、さらに一歩進んで、提示されたコンポーネントからプログラムを構築したいと思います。
アトミック操作とメモリ バリアによる同期
比較の出発点として、取得と解放のセマンティックを使用した典型的な消費者と生産者のワークフローを実装します。この仕事は、アトミックとメモリ バリアを使用して行います。
私たちのほとんどはアトミックに慣れているので、アトミックから始めましょう。それはメモリバリアには当てはまりません。それらは、C++ メモリ モデルに関する文献ではほとんど完全に無視されています。
アトミック操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | // acquireRelease.cpp
#include <atomic>
#include <thread>
#include <iostream>
#include <string>
std::atomic<std::string*> ptr;
int data;
std::atomic<int> atoData;
void producer(){
std::string* p = new std::string("C++11");
data = 2011;
atoData.store(2014,std::memory_order_relaxed);
ptr.store(p, std::memory_order_release);
}
void consumer(){
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire)));
std::cout << "*p2: " << *p2 << std::endl;
std::cout << "data: " << data << std::endl;
std::cout << "atoData: " << atoData.load(std::memory_order_relaxed) << std::endl;
}
int main(){
std::cout << std::endl;
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
delete ptr;
std::cout << std::endl;
}
|
このプログラムになじみがあることを願っています。 memory_order_consume への投稿で使用した私のクラシックです。グラフィックは、コンシューマ スレッド t2 がプロデューサー スレッド t1 からのすべての値を参照する理由を直接示しています。
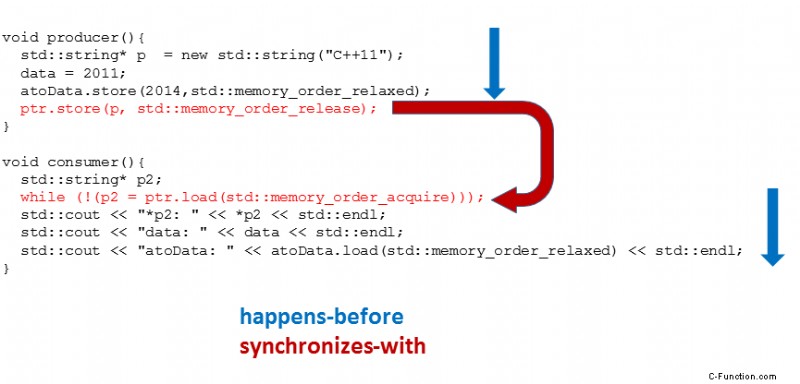
前に起こるため、プログラムは明確に定義されています。 関係は推移的です。 3 つの事前発生関係を組み合わせるだけです。
<オール>
しかし今、物語はよりスリリングです。ワークフローをメモリ バリアに合わせて調整するにはどうすればよいですか?
メモリーバリア
プログラムをメモリ バリアに移植するのは簡単です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | // acquireReleaseFences.cpp
#include <atomic>
#include <thread>
#include <iostream>
#include <string>
std::atomic<std::string*> ptr;
int data;
std::atomic<int> atoData;
void producer(){
std::string* p = new std::string("C++11");
data = 2011;
atoData.store(2014,std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_release);
ptr.store(p, std::memory_order_relaxed);
}
void consumer(){
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_relaxed)));
std::atomic_thread_fence(std::memory_order_acquire);
std::cout << "*p2: " << *p2 << std::endl;
std::cout << "data: " << data << std::endl;
std::cout << "atoData: " << atoData.load(std::memory_order_relaxed) << std::endl;
}
int main(){
std::cout << std::endl;
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
delete ptr;
std::cout << std::endl;
}
|
最初のステップは、セマンティックを取得および解放する操作のちょうど代わりに、セマンティックを取得および解放する対応するメモリ バリアを挿入することです (16 行目と 23 行目)。次のステップでは、取得または解放セマンティックを使用したアトミック操作をリラックス セマンティックに変更します (17 行目と 22 行目)。それはすでに機械的にでした。もちろん、1 つの取得または解放操作を対応するメモリ バリアに置き換えることしかできません。重要な点は、解放操作が取得操作と同期を確立することです。 関係、したがって happens-before
より視覚的な読者のために、画像内の全体の説明.
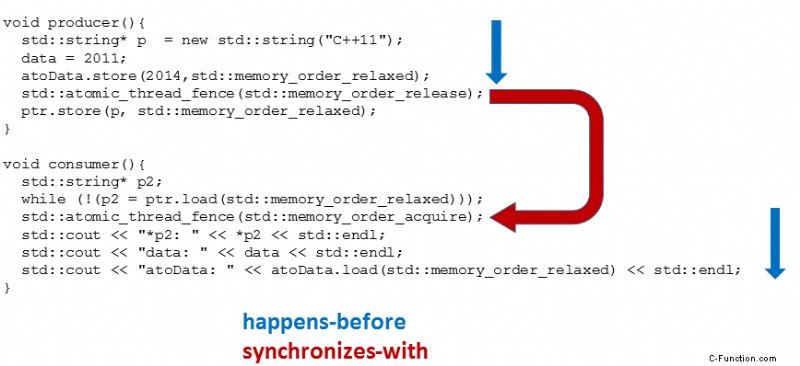
重要な質問は.メモリ バリアを取得した後の操作で、メモリ バリアを解放する前の操作の効果が見られるのはなぜですか? data は非アトミック変数であり、atoData は緩和されたセマンティックで使用されるため、両方を並べ替えることができます。しかし、それは不可能です。 std::atomic_thread_fence(std::memory_order_release) を解放操作として std::atomic_thread_fence(std::memory_order_acquire) と組み合わせて使用すると、部分的な並べ替えが禁止されます。私の推論を詳しくたどるには、投稿の冒頭にあるメモリ バリアの分析をお読みください。
明確にするために、すべての理由を要点に合わせて説明します。
<オール>最後に、プログラムの出力です。
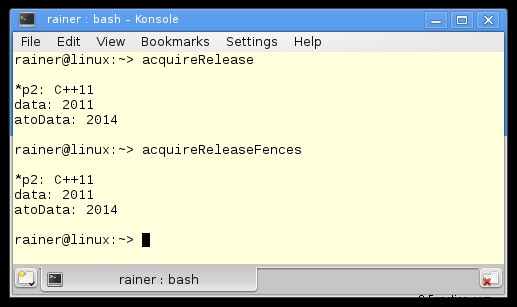
次は?
しかし今、最も弱いメモリ モデルに。リラックスしたセマンティックは、次の投稿のトピックになります。順序の制約はありません。