std::atomic_thread_fence の重要なアイデアは、アトミック操作なしでスレッド間の同期と順序付けの制約を確立することです。
std::atomic_thread_fence は単にフェンスまたはメモリ バリアと呼ばれます。したがって、std::atomic_thread_fence とは何かということがすぐにわかります。
std::atomic_thread_fence は防止し、特定の操作はメモリ バリアを克服できます。
メモリーバリア
しかし、それはどういう意味ですか?メモリバリアを克服できない特定の操作。どんな操作?鳥の観点から見ると、読み取りと書き込み、または読み込みと保存の 2 種類の操作があります。したがって、式 if(resultRead) return result はロードであり、その後にストア操作が続きます。
読み込み操作と保存操作を組み合わせるには、次の 4 つの方法があります。
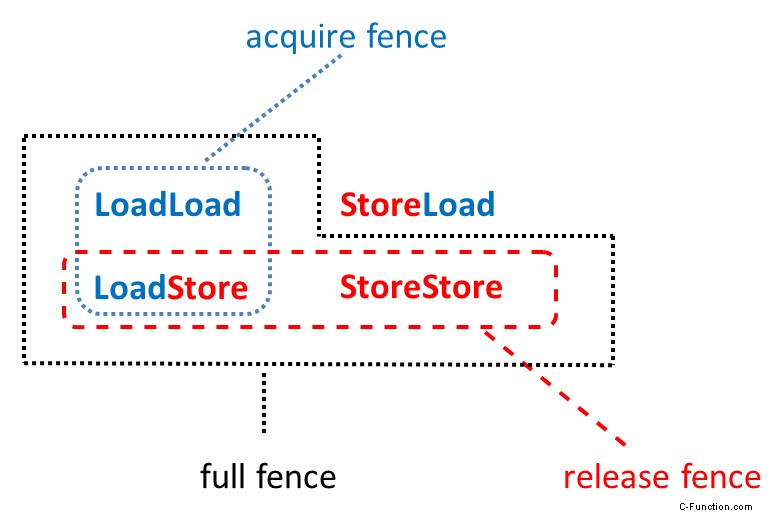
- ロードロード :ロードに続くロード。
- ロードストア: ストアに続く読み込み
- StoreLoad: ストアに続いてロード。
- StoreStore: ストアに続くストア
もちろん、ロードとストアの部分 (count++) で構成される、より複雑な操作があります。しかし、これらの操作は私の一般的な分類と矛盾しませんでした.
しかし、メモリバリアについてはどうですか?. LoadLoad、LoadStore、StoreLoad、または StoreStore などの 2 つの操作の間にメモリ バリアを配置する場合、特定の LoadLoad、LoadStore、StoreLoad、または StoreStore 操作を並べ替えることができないことが保証されます。非アトミックまたは緩和されたセマンティックのアトミックが使用されている場合、並べ替えのリスクが常に与えられます。
通常、3 種類のメモリ バリアが使用されます。それらはフル フェンス、取得フェンスと呼ばれます そしてフェンスを解放。 思い出させるためだけに。取得はロード、リリースはストア操作です。では、ロード操作とストア操作の 4 つの組み合わせの間に 3 つのメモリ バリアの 1 つを配置するとどうなるでしょうか?
- フル フェンス: 2 つの任意の操作の間の完全なフェンス std::atomic_thread_fence() により、これらの操作の並べ替えが防止されます。しかし、その保証は StoreLoad 操作には当てはまりません。並べ替えることができます。
- フェンスを取得: 取得フェンス std:.atomic_thread_fence(std::memory_order_acquire) は、取得フェンスの前の読み取り操作が、取得フェンスの後の読み取りまたは書き込み操作で並べ替えられるのを防ぎます。
- 解放フェンス: 解放フェンス std::memory_thread_fence(std::memory_order_release) は、リリース フェンスの前の読み取りまたは書き込み操作が、リリース フェンスの後の書き込み操作で並べ替えられるのを防ぎます。
フェンスの取得と解放の定義と、ロックフリー プログラミングに対するその結果を得るために、多くのエネルギーを費やしたことを認めます。特に、アトミック操作の取得と解放のセマンティックとの微妙な違いは、それほど簡単には取得できません。しかし、その点に到達する前に、定義を図で説明します。
メモリバリアの図解
メモリバリアを克服できるのはどのような操作ですか?次の 3 つの図を見てください。矢印が赤い納屋と交差している場合、フェンスはこの種の操作を防ぎます。
フルフェンス

もちろん、std::atomic_thread_fence() std::atomic_thread_fence(std::memory_order_seq_cst) の代わりに明示的に書くこともできます。デフォルトでは、フェンスには順次整合性が使用されます。完全なフェンスに使用される順次整合性は、std::atomic_thread_fence がグローバルな順序に従います。
フェンスを取得

解放フェンス

しかし、3 つの記憶の障壁をもっと簡潔に表すことができます。
メモリーバリアの概要
次は?
それが理論でした。練習は次の記事に続きます。この投稿では、取得フェンスの最初のステップを取得操作と比較し、解放フェンスと解放操作を比較します。 2 番目のステップでは、取得リリース操作を使用して生産者と消費者のシナリオをフェンスに移植します。