現代のコンピューターは信じられないほど高速で、常に高速になっています。ただし、コンピューターにはいくつかの重大な制約もあります。コンピューターは限られた一連のコマンドしかネイティブに理解できず、何をすべきかを正確に伝える必要があります。
コンピュータ プログラム (一般にアプリケーションとも呼ばれる) は、コンピュータが何らかのタスクを実行するために実行できる一連の命令です。プログラムを作成する作業をプログラミングと呼びます。プログラマーは通常、1 つまたは複数のテキスト ファイルに入力されたコマンドのリストであるソース コード (通常はコードと短縮されます) を生成することによってプログラムを作成します。
コンピュータを構成し、プログラムを実行する物理的なコンピュータ部品の集合は、ハードウェアと呼ばれます。コンピュータ プログラムがメモリに読み込まれ、ハードウェアが各命令を順次実行することを、プログラムの実行または実行と呼びます。
機械語
コンピュータの CPU は C++ を話すことができません。 CPU が直接理解できる限られた命令セットは、機械語 (または機械語または命令セット) と呼ばれます。
機械語命令の例を次に示します:10110000 01100001
コンピューターが最初に発明された当時、プログラマーは機械語でプログラムを直接作成する必要がありましたが、これは非常に困難で時間のかかる作業でした。
これらの手順がどのように構成されているかは、この概要の範囲を超えていますが、興味深い点が 2 つあります。まず、各命令は 1 と 0 のシーケンスで構成されます。個々の 0 または 1 は、2 進数または略してビットと呼ばれます。 1 つのコマンドを構成するビット数はさまざまです。たとえば、一部の CPU は常に 32 ビット長の命令を処理しますが、他の一部の CPU (x86 ファミリなど、おそらく使用している) は、可変長。
次に、2 進数の各セットが CPU によって解釈され、非常に特殊なジョブを実行するコマンドに変換されます。たとえば、これら 2 つの数値を比較 します。 、またはこの番号をそのメモリ位置に置きます .ただし、異なる CPU には異なる命令セットがあるため、1 つの CPU タイプ用に作成された命令は、同じ命令セットを共有しない CPU では使用できませんでした。これは、通常、プログラムがさまざまな種類のシステムに移植可能 (大幅な手直しなしで使用可能) ではなく、最初から書き直す必要があることを意味していました。
アセンブリ言語
機械語は人間が読んで理解するのが非常に難しいため、アセンブリ言語が発明されました。アセンブリ言語では、各命令は (一連のビットではなく) 短い略語で識別され、名前やその他の番号を使用できます。
上記と同じ命令をアセンブリ言語で次に示します:mov al, 061h
これにより、アセンブリは機械語よりも読み書きがはるかに簡単になります。ただし、CPU はアセンブリ言語を直接理解することはできません。代わりに、コンピューターで実行する前に、アセンブリ プログラムを機械語に変換する必要があります。これは、アセンブラと呼ばれるプログラムを使用して行われます。アセンブリ言語で書かれたプログラムは非常に高速になる傾向があり、アセンブリは今日でも速度が重要な場合に使用されています。
ただし、アセンブリにはまだいくつかの欠点があります。第 1 に、アセンブリ言語は、単純なタスクを実行するためにも、依然として多くの命令を必要とします。個々の命令自体はある程度人間が読めるものですが、プログラム全体が何をしているのかを理解するのは難しい場合があります (これは、各文字を個別に見て文を理解しようとするようなものです)。第 2 に、アセンブリ言語はまだあまり移植性がありません。ある CPU 用にアセンブリで書かれたプログラムは、別の命令セットを使用するハードウェアでは動作しない可能性が高く、書き直すか大幅に変更する必要があります。
高級言語
可読性と移植性の問題に対処するために、C、C++、Pascal (および後に Java、Javascript、Perl などの言語) などの新しいプログラミング言語が開発されました。これらの言語は、プログラマーがプログラムを実行するコンピューターの種類を気にせずにプログラムを作成できるように設計されているため、高水準言語と呼ばれます。
以下は、C/C++ での上記と同じ命令です:a = 97;
アセンブリ プログラムと同様に、高水準言語で記述されたプログラムは、実行する前にコンピューターが理解できる形式に変換する必要があります。これには、コンパイルと解釈という 2 つの主な方法があります。
コンパイラは、ソース コードを読み取り、実行可能なスタンドアロンの実行可能プログラムを生成するプログラムです。コードが実行可能ファイルに変換されると、プログラムを実行するためにコンパイラは必要ありません。当初、コンパイラは原始的で、低速で最適化されていないコードを生成していました。しかし、何年にもわたって、コンパイラは高速で最適化されたコードを生成するのに非常に優れており、場合によってはアセンブリ言語で人間が行うよりも優れた仕事をすることができます!
以下は、コンパイル プロセスの簡略化された表現です。
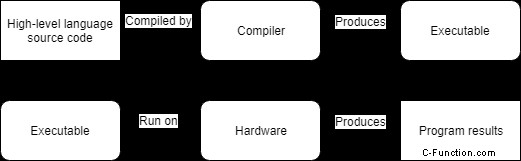
C++ プログラムは一般にコンパイルされるため、コンパイラについては後ほど詳しく説明します。
インタープリターは、最初に実行可能ファイルにコンパイルする必要なく、ソース コード内の命令を直接実行するプログラムです。インタープリターはコンパイラーよりも柔軟である傾向がありますが、プログラムを実行するたびに解釈プロセスを実行する必要があるため、プログラムを実行するときの効率は低くなります。これは、プログラムが実行されるたびにインタープリターが必要であることを意味します。
以下は、解釈プロセスを簡略化したものです:

オプションの読み物
コンパイラとインタプリタの利点の良い比較は、ここにあります。
ほとんどの言語はコンパイルまたは解釈できますが、伝統的に C、C++、Pascal などの言語はコンパイルされますが、Perl や Javascript などの「スクリプト」言語は解釈される傾向があります。 Java などの一部の言語では、この 2 つを組み合わせて使用します。
高水準言語には、多くの望ましい特性があります。
まず、高水準言語は、コマンドが日常的に使用する自然言語に近いため、読み書きがはるかに簡単です。第二に、高水準言語は低水準言語と同じタスクを実行するために必要な命令が少なくて済み、プログラムがより簡潔で理解しやすくなります。 C++ では a = b * 2 + 5; のようなことができます 一行で。アセンブリ言語では、これには 5 つまたは 6 つの異なる命令が必要です。
第 3 に、プログラムはさまざまなシステム用にコンパイル (または解釈) でき、別の CPU で実行するようにプログラムを変更する必要はありません (その CPU 用に再コンパイルするだけです)。例:
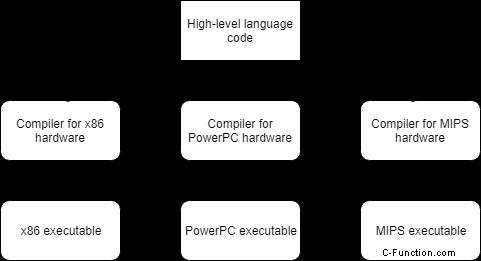
移植性には 2 つの一般的な例外があります。 1 つ目は、Microsoft Windows などの多くのオペレーティング システムには、コードで使用できるプラットフォーム固有の機能が含まれていることです。これらを使用すると、特定のオペレーティング システム用のプログラムを簡単に作成できますが、移植性が犠牲になります。これらのチュートリアルでは、プラットフォーム固有のコードは避けます。
一部のコンパイラは、コンパイラ固有の拡張機能もサポートしています。これらを使用すると、同じ拡張機能をサポートしていない他のコンパイラでプログラムをコンパイルできなくなります。これらについては、コンパイラをインストールした後で詳しく説明します。
ルール、ベスト プラクティス、および警告
これらのチュートリアルを進めていくと、次の 3 つのカテゴリの下で多くの重要なポイントが強調されます。
ルール
ルールはしなければならない指示です 言語の必要に応じて実行します。ルールに従わないと、通常、プログラムが機能しなくなります。
ベスト プラクティス
ベスト プラクティスとは、すべきことです。 その方法は、一般的に標準または強く推奨されると考えられているためです。つまり、誰もがそのようにしている (そうでなければ、人々が予期しないことをしていることになる) か、代替案よりも優れているかのどちらかです。
警告
警告は、すべきではないものです そうすれば、一般に予期しない結果につながるからです。