始める前に
このブログ投稿では、ハンドヘルド デバイスでは正しく表示されない可能性がある iframe、インタラクティブな SVG ファイル、およびグラフを取り上げています。申し訳ありませんが、グラフはインタラクティブなので、拡大して正確な値を確認できます。
もし私がコンパイラなら、単純にすべてのバイトをあなたのバイナリ
06 については、興味深い熱烈な議論がいくつかありました。 最近。
17 ツールボックスに入れておいた方がよいツールになることは間違いありません。コンセンサスが得られれば、いずれ何らかのバージョンが採用されると確信しています (その提案の有用性に同意していない人をまだ見つけていません)。
しかし、(何でも) 標準化は難しいので、それまでの間、22 の動機の 1 つを探りたいと思います。 :
大規模な配列のコンパイルは、非常に時間とリソースを消費します。あらゆるコンパイラに。
どうして?さて…
もちろん、ThePhd が示唆しているように、このエクササイズが CPU に負担をかけている場合、RAM に与える影響に比べれば大したことではありません:
50000000 整数、これは約 200MB で、少しばかげているかもしれません。大きな配列には有効な使用例があります。
たとえば、Qt のリソース システムは、埋め込みリソース用のファイル システムを作成します。30 、暗号関数などはルックアップ テーブルに依存しています。これらの機能を 49 にしたい場合 、リンカー トリックを使用することはできません (リンカー トリックを使用したいのは誰ですか?)
お気付きかもしれませんが、私は Unicode プロパティに取り組んでおり、注意深くビット パッキングを行っても、これらのテーブルには何千もの要素が含まれています。
Twitter には他にも多くの興味深いユースケースがありました。たとえば、組み込みプラットフォームをターゲットとするバイナリにニューラル ネットワークの重みを埋め込む人々などです!
#cplusplus twitter さん、C++ の非常に大きな組み込みバイナリ データ / const int 配列のユース ケースは何ですか?
— コランタン (@Cor3ntin) 2019 年 12 月 21 日プログラムを大幅に高速化するためのよく知られたトリックがあります:文字列リテラルを使用してください!
int array[] = {1, 1, /*, ..., */ 1, 1}; //slow
const char* literal = // Fast
"\x00\x00\x00\x01\x00\x00\x00\x01"
/*....*/
"\x00\x00\x00\x01\x00\x00\x00\x01";
残念ながら、58 というキャッチがあります。 65535 バイトを超える文字列リテラルは使用できません。
この制限を解除することは ABI に違反するため、起こりそうにないと考えています。私は ABI の安定性が嫌いです。
とにかく、疑問が生じます:なぜ文字列リテラルは配列よりもはるかに高速なのですか?コンパイラの内部を覗くのに役立つツールがいくつかあります.そのようなツールの 1 つが 61 です。 71 のオプション これは… その内部表現をよくダンプします。そのツールは、コンパイラ エクスプローラで便利に利用できます:
これが原因です。Clang は各数値を独自の AST NODE として表しますが、文字列リテラルは常に 1 つのノードであり、各バイトは 1 バイトで表されます。
85 以下を追跡する必要があります:
- 価値
- その値の型情報 (constness、signedness、exact type (
99を含む) 、104など) - その値のソースの場所
- 他にもいくつかあります。
最終的に、各ノードは 4 バイトの値に対して約 100 バイトを十分に格納できます。
さらに重要なことに、 115 の各部分式 完全に異なる型を持つ可能性があり、完全な式、関数呼び出し、ラムダ、さらにはテンプレートのインスタンス化である可能性があります.
struct a {
operator int() const;
};
template <typename T>
struct V {
static constexpr int v = 42;
};
int array[] = {a(), V<int>::v, []<typename T>(T i) {return T(); }(0)};
同時に、イニシャライザ リストは、クラス インスタンス、配列、集約、125 など、あらゆるものを初期化するために使用できます。 、および上記すべてのテンプレート バージョン。
C++ での初期化は簡単ではありません。 clang では、137 の 1 万行 その作業のほとんどを行い、整数の単純な配列であることを単純に期待したものの各要素について、その配列の型に実際に変換可能であることを確認します。
これは、貧弱なコンパイラにとっては大変な作業です。
整数配列のパフォーマンスの向上
整数またはバイトの配列がある程度一般的であることを考えると、そのユースケースのパフォーマンスを改善できますか?llvm のクローンを作成する時間です!
Clang は大規模なコードベースです。私はすでに少し遊んでいましたが、特に印象的なことは何もしていませんでした. サイズと複雑さは別として、Clang は依然としてコンパイラです.いくつかのビットがあります:
- 前処理とトークン化を行うレクサー
- パーサー
- セマンティック分析
- LLVM IR 生成
- IR をオブジェクト コードに変換する魔法
どこから始めればよいでしょうか?私の最初のアイデアは、開発者が特定の方法で配列を解析するようにコンパイラに指示できるように、属性を導入することでした:
[[clang::literal_array]]
int array[] = {1, 2, 3, 4};
しかし、コンパイラに効率的であるように手動で指示しなければならないのは面倒であり、メリットも限られていることにすぐに気付きました。
新しい計画:パターンを自動的に検出して最適化します。大きなコードベースを回避するには、プロファイラー、デバッガー、コードの読み取りなど、さまざまな方法があります。たくさん読んでください。
すぐに、探していたものが見つかりました:
/// ParseBraceInitializer - Called when parsing an initializer that has a
/// leading open brace.
///
/// initializer: [C99 6.7.8]
/// '{' initializer-list '}'
/// '{' initializer-list ',' '}'
/// [GNU] '{' '}'
///
/// initializer-list:
/// designation[opt] initializer ...[opt]
/// initializer-list ',' designation[opt] initializer ...[opt]
///
ExprResult Parser::ParseBraceInitializer();
有益なコメントにも恵まれました!その関数は 147 を返します これには、リストの要素ごとに 1 つの部分式があります。これが問題であることはわかっているので、別のことをしましょう!
リスト全体を (右中括弧まで) Lex してみましょう。すべてのトークンが数値定数である場合は、新しいタイプの式を返します:
// Try to parse the initializer as a list of numeral literal
// To improve compile time of large arrays
if(NextToken().is(tok::numeric_constant)) {
ExprResult E = ParseListOfLiteralsInitializer();
if(!E.isInvalid()) {
return E;
}
//otherwise carry on
}
150 の実装 難しいことではありませんでした。Clang には、暫定的な解析を行い、仮定がうまくいかない場合にレクサーの状態を元に戻す機能があります。
しかし、新しい 164 が必要になりました と入力して戻ります。もう少し作業が必要です。175 型はいたるところで処理する必要があり、何百もの場所を変更する必要があります。この記事を書いている時点で、私はその作業の 10% しかできていません.
悪い名前を付けました
class ListOfLiteralExpr : public Expr {
public:
ListOfLiteralExpr(ASTContext &Context,
SourceLocation LBraceLoc,
ArrayRef<llvm::APInt> Values,
QualType Ty,
SourceLocation RBraceLoc);
};
最初のドラフト:診断目的の各ブレースの場所、値のリスト、各要素の型 (int、long、unsigned バージョンなど)。以上です。187 に注意してください。 すでに必要以上に大きく複雑です。これについては後で詳しく説明します。主な最適化は、各要素が同じ型であると仮定することです:たとえば 198 に遭遇した場合 、救済して207を取る必要があります
私のアプローチは特に効率的ではありません.おそらく小さなリストを 213 として解析する方が良いでしょう. いずれにせよ、要素が 2 つ未満のリストを 226 としてパースすることは決してありません その理由はすぐに明らかになります。
これまでのところ、230 よりもはるかに高速に解析できる式の型を作成することに成功しています。 .それでも 244 ほど速くはありません ただし:文字列は 1 つのトークンですが、整数ごとに解析するトークンがいくつかあります.しかし、レクサーはかなり高速です.もっと大きな問題があるため、そのままにしておきます.
私がその道を歩み始めたときは気がつきませんでしたが、すぐに恐ろしいことに気づきました:257 の最適化されたバージョンである式を導入しました。 .したがって、266 の圧倒的な複雑さに対処する必要があります。 C++ と Clang の両方の初期化に関する十分な知識が必要なファイルです。
どちらも知りませんでした。
わかりました、それは完全に真実ではありません:
また、C、OpenCL、および GCC と MSVC 拡張機能の詳細も理解する必要があります。私は失敗する運命にありました!
主な問題は、Clang が式で動作することです。My 274 type は式ですが、その要素はそうではありません!
それでもなお、新しいクラスを作成することで、ある程度の進歩がありました
class AbstractInitListExpr : public Expr {};
class ListOfLiteralExpr : public AbstractInitListExpr {};
class InitListExpr : public AbstractInitListExpr {};
これにより、 280 間でコードを機械的に共有できました そして既存の 292 、両方のクラスが要素の数や型などの必要な情報を持っていた場所 要素 (ただし、要素ではない) 自体の。
302 について理解する 私が収集したものから、clang は初期化リストで複数のパスを操作し、最終的な初期化の前に実行する一連の操作を構築します.C++ と C はどちらも少しクレイジーです:
struct A {
int a;
struct {
int b;
int c;
};
int d;
int e;
} a = {1, 2, 3, .e = 4};
int x [10] = { [1] = 10};
変換、オーバーロードなどを解決する必要があります。正直に言うと、自分が何をしているのかわかりません.
しかし、私は何かをハッキングしました
void InitializationSequence::InitializeFrom(
Sema &S,
const InitializedEntity &Entity,
const InitializationKind &Kind,
MultiExprArg Args,
bool TopLevelOfInitList,
bool TreatUnavailableAsInvalid);
物事をどこに置くかを見つけることは仕事の半分です:私はそのコードをまとめました:それは厄介でバグだらけです:たとえば、長いものから短いものへの変換について文句を言うことはありませんそして 312 を変換する 323 へ は効率的ではありません。大規模な配列のために、一般的なケースにペナルティを課しています。
if(auto* ListExpr = dyn_cast_or_null<ListOfLiteralExpr>(Initializer)) {
// TODO CORENTIN: HANDLE MORE CASES
if (const ArrayType *DestAT = Context.getAsArrayType(DestType)) {
//Nasty
if(DestAT->getElementType()->isIntegerType()) {
TryListOfLiteralInitialization(S, Entity, Kind, ListExpr, *this,
TreatUnavailableAsInvalid);
return;
}
}
else {
//Convert back ListOfLiteralExpr to InitListExpr
}
}
しかし、それは動作します ほとんどの場合 - テンプレートではなく、まったく処理していないので 330 コンパイルされません。
348 非常に単純です - 重要な詳細を省略したおかげで:初期化しようとしている型が正しいサイズ (または不完全なサイズでも機能します!) の配列であることを確認するだけです。
最終的に、約 12000 行で 350 、私たちはその事件全体に成功した、しかし逆境的な結論に達します:
VDecl->setInit(Init);
構文解析と意味解析が完了しました (これは実際には 1 つの大きなステップにすぎません。C++ の構文解析はコンテキストに大きく依存します。これで夜中に目が覚めないことを願っています)。
あとはコードを生成するだけです。その部分はほとんど理解できませんが、 366 コード生成 (IR) を処理するコードの一部:378 (Aggregate Expression Emitter) は、十分に簡単であることが証明されました:
コードのさらに別の部分を延期することもできます:定数式の評価では、すべての constexpr の利点と定数の折り畳みが行われます:
388 で訪問者を追加する 簡単でした:
bool ArrayExprEvaluator::VisitListOfLiteralExpr(const ListOfLiteralExpr *E) {
const ConstantArrayType *CAT = Info.Ctx.getAsConstantArrayType(E->getType());
assert(CAT && "ListOfLiteralExpr isn't an array ?!");
QualType EType = CAT->getElementType();
assert(EType->isIntegerType() && "unexpected literal type");
unsigned Elts = CAT->getSize().getZExtValue();
Result = APValue(APValue::UninitArray(),
std::min(E->getNumInits(), Elts), Elts);
for(unsigned I = 0; I < E->getNumInits(); I++ )
Result.getArrayInitializedElt(I) = APSInt(E->getInit(I));
return true;
}
私は後でそれを最適化しました.しかし、いくつかの悪いpythonスクリプトのおかげで、いくつかのベンチマークを実行するのに十分です
f.write("int a [] = {")
f.write(",".join(["1"] * elems))
f.write("}; int main (int argc, char**) { return a[argc]; }")
コンパイル時間を 3 倍改善しました。悪くない!200MB のデータを含むファイルを生成するのに 10 秒もかかりません。
391 の使用 402 について詳しく読むことができます。 :こちら。特に、独自のコードのコンパイル時間を測定および最適化するための非常に便利なツールです!
クロムは、レンダリングされたファイルをハッキングすることで、複数のフレームグラフを比較することさえサポートしていることが判明しました。 、したがって、png が行う必要があります:
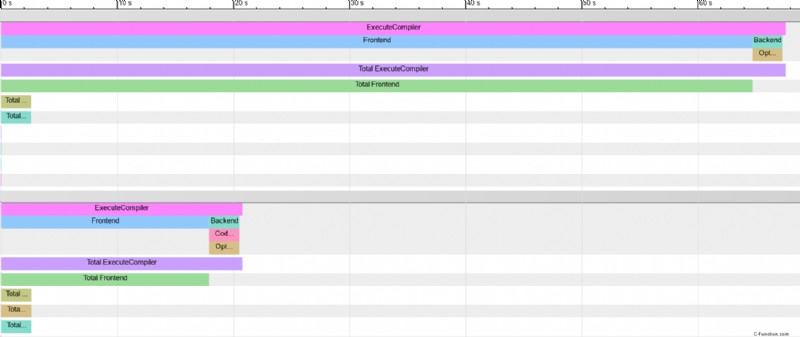
興味深いことに、メモリ使用量はあまり改善されていないようです。
小さな配列のコンパイル時間はノイズの中で失われます。代わりに、以下のグラフでは、指定されたサイズの 1000 個の配列のコンパイル時間を測定し、結果を 1000 で割って、配列あたりの平均時間を求めています。
小さな配列では改善が見られるように見えます.それを少し塩を加えて考えてください.変更はおそらく非配列のケースを悲観的にします.しかし、下のグラフでは、すべての配列サイズの平均でコンパイル時間が70%以上減少しています.(小さな値の場合、ベンチマーク ソース ファイルには、指定されたサイズの 1000 個の配列が含まれます)
AstSmtWriter とモジュール
プリコンパイル済みヘッダー、モジュール ヘッダー ユニット、およびモジュール インターフェイスは、同じバイナリ形式の一部を共有しています。421 と 436 ステートメントのバイナリシリアル化を担当します(および式、式はclangのステートメントです-意味があります)。
モジュールが大きな配列にどのように役立つかを見たかったので、新しく作成された 449 のシリアル化を実装しました .
同時に、実装をもう少しきれいにすることにしました。これまで、値を 457 に格納していました ただし、clang には独自のアロケーターがあり、追加のヒープスペースが必要な式は、オブジェクトの後に余分なデータを配置するようアロケーターに要求できます。
class ListOfLiteralExpr final: public AbstractInitListExpr,
private llvm::TrailingObjects<ListOfLiteralExpr, unsigned, char>
{
unsigned numTrailingObjects(OverloadToken<unsigned>) const {
return 1;
}
unsigned numTrailingObjects(OverloadToken<char>) const {
return *getTrailingObjects<unsigned>();
}
ListOfLiteralExpr*
ListOfLiteralExpr::Create(ASTContext &Context,
SourceLocation LBraceLoc,
ArrayRef<uint64_t> Values,
QualType Ty,
SourceLocation RBraceLoc) {
void *Mem = Context.Allocate(totalSizeToAlloc<unsigned, char>(1,Bytes),
alignof(ListOfLiteralExpr));
auto * E = new (Mem)
ListOfLiteralExpr(Context, LBraceLoc, Values, Ty, RBraceLoc);
*E->getTrailingObjects<unsigned>() = Bytes;
return E;
}
そこには複雑な機械がたくさんあります!これは記憶に残るでしょう:
464
471 ?
はい、481 任意の種類の整数リテラルを格納するためのものであり、これらは異なるサイズにすることができます。したがって、495 の配列を格納します 代わりに、char の配列と 500 を格納できます。 整数値のサイズに対応するタイプを入力します。ターゲット プラットフォームに 8 ビット バイトがない場合、これは完全に失敗します。まったく気にしませんでした。
そのトリックはエレガントに実装できます:
#include <tuple>
uint64_t f(const char* bytes, unsigned byte_size, unsigned index) {
template for (constexpr auto dummy :
std::tuple<uint8_t, uint16_t, uint32_t, uint64_t>()) {
if(byte_size == sizeof(dummy)) {
return reinterpret_cast<const decltype(dummy)*>(bytes)[index];
}
}
__builtin_unreachable();
}
あっ、待って。これは C++23 までコンパイルされません。 (ただし、コンパイラ エクスプローラーではコンパイルされます)。多くの if ステートメントを手動で作成する必要があります。またはMacrを定義してください…
そこにも行かないでください。出来ることならどうぞ。あえて言います。
すべての整数が適切にメモリにパックされたので、シリアル化コードは簡単です:
void ASTStmtWriter::VisitListOfLiteralExpr(ListOfLiteralExpr* E) {
VisitExpr(E);
const auto S = E->sizeOfElementsAsUint64();
Record.writeUInt64(S);
Record.AddSourceLocation(E->getLBraceLoc());
Record.AddSourceLocation(E->getRBraceLoc());
Record.AddTypeRef(E->getInitsType());
Record.writeUInt64(E->getNumInits());
const auto Elems = E->getElementsAsUint64();
Record.append(Elems, Elems + S);
Code = serialization::EXPR_INIT_LITERALS_LIST;
}
少しごまかしたかもしれません。シリアル化の基になる型は 511 のストリームです。 .だから私は自分のバイトが 524 の倍数であることを確認しました .それは少し厄介かもしれません.でも気にしないから
536 を使用しますが、必要なバイト数だけを使用します。 各キャラクターごとに。誰も気にする必要はありません:ディスクは安価です読書は反対です。
ところで、これがコンパイル済みモジュールの配布がひどい考えである理由です。人々がそうし始めると、シリアライゼーションは決して最適化できません。しないでください。
モジュールでいくつかのベンチマークを実行できるようになりました
// Baseline
int i[] = {1, /*...*/, 1};
int main() {}
//Module
export module M;
export int i[] = {1, /*...*/, 1};
//importer
import M;
int main() {}
モジュールはいくつかのパフォーマンス上の利点を提供しているように見えますが、これらの利点は、バイナリ データが 100 MB を超える、配列が非常に大きくなるまで明らかではありません.
ほろ苦い結論
私が自分自身に寛大であるなら、本番環境で使用可能で、最終的には LLVM でマージできるものに 20% かかるかもしれません。多くの ToDo のうち:
- 浮動小数点および文字リテラルのサポート:
- Sema Init でのより適切で健全な統合
- ツールへの統合
- 配列の constexpr コンパイルをさらに改善できるかどうかを確認してください
あと数週間の努力が必要です。確かに、客観的に言えば、clang は著しく速くなりました。一部のワークロードでは.非現実的なワークロードかもしれません.プロファイラときれいなグラフは魅力的です.オーバーフィッティングは途方もない数を生成する確実な方法です.そしてその代償はclangの複雑さの追加です.その追加の複雑さはトラブルに見合うだけの価値がありますか?私はそれに答える資格があるとは思いません.真実は、私には明らかです.いくつかの 540 所々にかかわらず、LLVM は十分に最適化されたマシンであり、抽象化のレイヤーを剥がすことによってのみいくつかの改善を得ることができました.clang のメンテナーは複雑さが増したことを歓迎しますか?
しかし、別の見方もできます:人々はコンパイル時間を気にし、コンパイル速度をわずかに向上させるためにコードの保守性を犠牲にするほどです。
コンパイル時間は、人々が最適化してはならない最後のものであることを嘆くことができます.Clang のあちこちの数マイクロ秒は、何百万人もの人々に利益をもたらします.
もう一度言いますが、そのエネルギーを 553 に入れる方が賢明でしょう。 、これは、ここで紹介するすべての最適化を桁違いに上回っています!
リファレンスとツール
このブログ投稿は、最終的に約 1 週間の作業を表しています。大規模なコードベースに直面したため、強力なハードウェアとツールしかお勧めできません:
- パフォーマンス分析のための Valgrind、Vtune、Perf、Hotspot
- C-Reduce は、コンパイラのクラッシュを再現する最小のコードを見つけるための非常に便利なツールです
- 必要な唯一の C++ コンパイラであるコンパイラ エクスプローラ
- FlameGraph と Plotly を使用して、現在のブログ投稿のグラフを生成します。いくつかの不快な Python スクリプトを使用します。
LLVM のソースは、簡単に複製できる素晴らしい Github リポジトリにあります。
その記事のパッチはここにあります。
何も期待しないでください:ブログ投稿主導の開発です!
読んでくれてありがとう。感想を聞かせて!