私のお気に入りのディスパッチ テーブルの例は、最新の C++ の機能が連携していかに優れているかを示しています。ディスパッチ テーブルは、関数へのポインタのテーブルです。私の場合、これはポリモーフィック関数ラッパーへのハンドルのテーブルです。
しかし、最初に、現代の C++ とはどういう意味ですか。 C++11 のディスパッチ テーブル機能を使用します。この投稿 C++14 をタイムラインに追加しました。なんで?後で見ます。
発送表
Arne Mertz のおかげで、C++11 機能の均一な初期化を初期化リストと組み合わせて使用しました。これにより、次の例がさらに改善されました。
この例は、文字を関数オブジェクトにマップする単純なディスパッチ テーブルを示しています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | // dispatchTable.cpp
#include <cmath>
#include <functional>
#include <iostream>
#include <map>
int main(){
std::cout << std::endl;
// dispatch table
std::map< const char , std::function<double(double,double)> > dispTable{
{'+',[](double a, double b){ return a + b;} },
{'-',[](double a, double b){ return a - b;} },
{'*',[](double a, double b){ return a * b;} },
{'/',[](double a, double b){ return a / b;} } };
// do the math
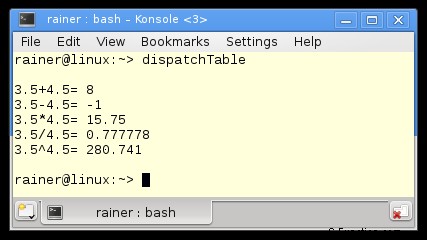
std::cout << "3.5+4.5= " << dispTable['+'](3.5,4.5) << std::endl;
std::cout << "3.5-4.5= " << dispTable['-'](3.5,4.5) << std::endl;
std::cout << "3.5*4.5= " << dispTable['*'](3.5,4.5) << std::endl;
std::cout << "3.5/4.5= " << dispTable['/'](3.5,4.5) << std::endl;
// add a new operation
dispTable['^']= [](double a, double b){ return std::pow(a,b);};
std::cout << "3.5^4.5= " << dispTable['^'](3.5,4.5) << std::endl;
std::cout << std::endl;
};
|
魔法はどのように機能しますか?私の場合、ディスパッチ テーブルは、const char と std::function
20 行目から 23 行目で関数オブジェクトを使用しています。したがって、20 行目の dispTable['+'] の呼び出しは、ラムダ関数 [](double a, double b){ return a によって初期化された関数オブジェクトを返します。 + b; } (14行目)。関数オブジェクトを実行するには、2 つの引数が必要です。これらを dispTable['+'](3.5, 4.5) という式で使用します。
std::map は動的データ構造です。したがって、実行時に '^' 操作 (27 行目) を追加して使用できます。これが計算です。
それでも、簡単な説明がありません。なぜこれが C++ の私のお気に入りの例なのですか?
Python と同様
私はよくPythonのセミナーを行っています。 Python を簡単に使用できるようにするための私のお気に入りの例の 1 つは、ディスパッチ テーブルです。 Python が case ステートメントを必要としないのは、これが理由です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # dispatchTable.py
dispTable={
"+": (lambda x, y: x+y),
"-": (lambda x, y: x-y),
"*": (lambda x, y: x*y),
"/": (lambda x, y: x/y)
}
print
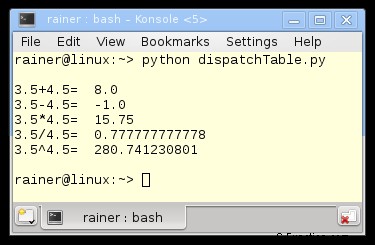
print "3.5+4.5= ", dispTable['+'](3.5, 4.5)
print "3.5-4.5= ", dispTable['-'](3.5, 4.5)
print "3.5*4.5= ", dispTable['*'](3.5, 4.5)
print "3.5/4.5= ", dispTable['/'](3.5, 4.5)
dispTable['^']= lambda x, y: pow(x,y)
print "3.5^4.5= ", dispTable['^'](3.5, 4.5)
print
|
実装は、Python の機能に基づいています。 std::map、std::function、およびラムダ関数のおかげで、C++11 で同じ例を使用して、C++ の表現力を強調できるようになりました。 10 年前には夢にも思わなかった事実です。
ジェネリック ラムダ関数
私はほとんどそれを忘れていました。ラムダ関数は C++14 でより強力になります。ラムダ関数は、その引数の型を自動的に推測できます。この機能は、auto による自動型推論に基づいています。もちろん、ラムダ関数と自動型推論は関数型プログラミングの特徴です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | // generalizedLambda.cpp
#include <iostream>
#include <string>
#include <typeinfo>
int main(){
std::cout << std::endl;
auto myAdd= [](auto fir, auto sec){ return fir+sec; };
std::cout << "myAdd(1, 10)= " << myAdd(1, 10) << std::endl;
std::cout << "myAdd(1, 10.0)= " << myAdd(1, 10.0) << std::endl;
std::cout << "myAdd(std::string(1),std::string(10.0)= "
<< myAdd(std::string("1"),std::string("10")) << std::endl;
std::cout << "myAdd(true, 10.0)= " << myAdd(true, 10.0) << std::endl;
std::cout << std::endl;
std::cout << "typeid(myAdd(1, 10)).name()= " << typeid(myAdd(1, 10)).name() << std::endl;
std::cout << "typeid(myAdd(1, 10.0)).name()= " << typeid(myAdd(1, 10.0)).name() << std::endl;
std::cout << "typeid(myAdd(std::string(1), std::string(10))).name()= "
<< typeid(myAdd(std::string("1"), std::string("10"))).name() << std::endl;
std::cout << "typeid(myAdd(true, 10.0)).name()= " << typeid(myAdd(true, 10.0)).name() << std::endl;
std::cout << std::endl;
}
|
11 行目では、一般的なラムダ関数を使用しています。この関数は、引数 fir および second に任意の型を指定して呼び出すことができ、さらに戻り値の型を自動的に推定します。ラムダ関数を使用するために、ラムダ関数に myAdd という名前を付けました。行 13 ~ 17 は、ラムダ関数の適用を示しています。もちろん、コンパイラが戻り値の型としてどの型を導出するかに興味があります。そのために、21 行目から 25 行目で typeid 演算子を使用します。この演算子にはヘッダー
typeid 演算子はあまり信頼できません。実装に依存する C 文字列を返します。 C 文字列が型ごとに異なることも、プログラムの呼び出しごとに C 文字列が同じであることも保証されていません。しかし、私たちのユースケースでは、typeid 演算子は十分に信頼できます。
私のデスクトップ PC は壊れているので、cppreference.com でプログラムを実行します。
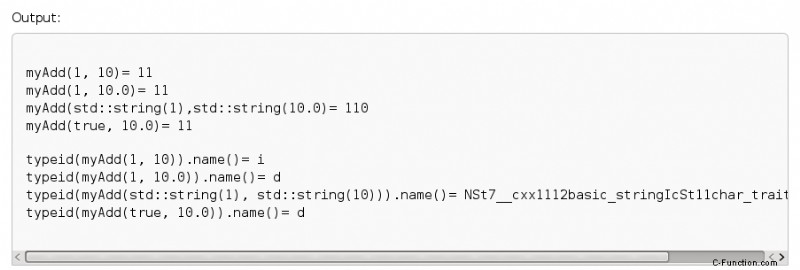
出力は、さまざまな戻り値の型を示しています。 C 文字列 i および d は、int 型および double 型を表します。 C++ 文字列の型はあまり読みやすくありません。しかし、std::string は std::basic_string のエイリアスであることがわかります。
次は?
次の投稿では、C++ の近未来の関数型未来について書きます。 C++17 と C++20 では、C++ の機能面がより強力になります。