std::string_view の目的は、他の誰かがすでに所有していて、変化しないビューのみが必要なデータをコピーしないようにすることです。したがって、この投稿は主にパフォーマンスに関するものです。
今日は、C++17 の主な機能について書きます。
std::string_view について少し知っていると思います。そうでない場合は、まず以前の投稿 C++17 - ライブラリの新機能 をお読みください。 C++ 文字列は、データをヒープに格納するシン ラッパーのようなものです。そのため、C および C++ 文字列を処理するときにメモリ割り当てが発生することがよくあります。見てみましょう。
小さな文字列の最適化
この段落を短い文字列の最適化と呼んだ理由は、数行でわかります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | // sso.cpp
#include <iostream>
#include <string>
void* operator new(std::size_t count){
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str){}
int main() {
std::cout << std::endl;
std::cout << "std::string" << std::endl;
std::string small = "0123456789";
std::string substr = small.substr(5);
std::cout << " " << substr << std::endl;
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(small);
getString("0123456789");
const char message []= "0123456789";
getString(message);
std::cout << std::endl;
}
|
6 行目から 9 行目でグローバル演算子 new をオーバーロードしました。したがって、どの操作がメモリ割り当てを引き起こすかがわかります。来て。簡単だ。行 19、20、28、および 29 でメモリ割り当てが発生します。ここに数字があります:
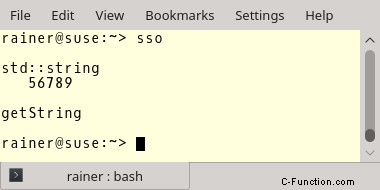
なに…?文字列はそのデータをヒープに保存します。ただし、文字列が実装依存のサイズを超える場合にのみ当てはまります。 std::string のこのサイズは、MSVC と GCC では 15、Clang では 23 です。
逆に、小さな文字列は文字列オブジェクトに直接格納されます。したがって、メモリ割り当ては必要ありません。
これからは、私の文字列は常に少なくとも 30 文字になります。したがって、小さな文字列の最適化について考える必要はありません。もう一度始めましょう。今度は長い文字列から始めましょう。
メモリ割り当ては不要
これで、std::string_view が明るく輝きます。 std::string とは対照的に、std::string_view はメモリを割り当てません。これが証拠です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | // stringView.cpp
#include <cassert>
#include <iostream>
#include <string>
#include <string_view>
void* operator new(std::size_t count){
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str){}
void getStringView(std::string_view strView){}
int main() {
std::cout << std::endl;
std::cout << "std::string" << std::endl;
std::string large = "0123456789-123456789-123456789-123456789";
std::string substr = large.substr(10);
std::cout << std::endl;
std::cout << "std::string_view" << std::endl;
std::string_view largeStringView{large.c_str(), large.size()};
largeStringView.remove_prefix(10);
assert(substr == largeStringView);
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(large);
getString("0123456789-123456789-123456789-123456789");
const char message []= "0123456789-123456789-123456789-123456789";
getString(message);
std::cout << std::endl;
std::cout << "getStringView" << std::endl;
getStringView(large);
getStringView("0123456789-123456789-123456789-123456789");
getStringView(message);
std::cout << std::endl;
}
|
もう一度。メモリ割り当ては 24、25、41、43 行で行われます。しかし、31、32、50、51 行の対応する呼び出しでは何が行われているのでしょうか。メモリ割り当てなし!
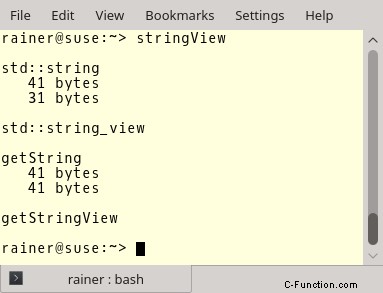
それは印象的です。メモリ割り当ては非常にコストのかかる操作であるため、これはパフォーマンスの向上であると想像できます。既存の文字列の部分文字列を作成すると、このパフォーマンスの向上がよくわかります。
O(n) 対 O(1)
std::string と std::string_view には両方のメソッド substr があります。 std::string のメソッドは部分文字列を返しますが、std::string_view のメソッドは部分文字列のビューを返します。これはそれほどスリリングではないように聞こえます。しかし、両方の方法には大きな違いがあります。 std::string::substr には線形複雑性があります。 std::string_view::substr の複雑さは一定です。つまり、std::string に対する操作のパフォーマンスは部分文字列のサイズに直接依存しますが、std::string_view に対する操作のパフォーマンスは部分文字列のサイズに依存しません。
今、私は興味があります。簡単なパフォーマンス比較をしてみましょう。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | // substr.cpp
#include <chrono>
#include <fstream>
#include <iostream>
#include <random>
#include <sstream>
#include <string>
#include <vector>
#include <string_view>
static const int count = 30;
static const int access = 10000000;
int main(){
std::cout << std::endl;
std::ifstream inFile("grimm.txt");
std::stringstream strStream;
strStream << inFile.rdbuf();
std::string grimmsTales = strStream.str();
size_t size = grimmsTales.size();
std::cout << "Grimms' Fairy Tales size: " << size << std::endl;
std::cout << std::endl;
// random values
std::random_device seed;
std::mt19937 engine(seed());
std::uniform_int_distribution<> uniformDist(0, size - count - 2);
std::vector<int> randValues;
for (auto i = 0; i < access; ++i) randValues.push_back(uniformDist(engine));
auto start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i ) {
grimmsTales.substr(randValues[i], count);
}
std::chrono::duration<double> durString= std::chrono::steady_clock::now() - start;
std::cout << "std::string::substr: " << durString.count() << " seconds" << std::endl;
std::string_view grimmsTalesView{grimmsTales.c_str(), size};
start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i ) {
grimmsTalesView.substr(randValues[i], count);
}
std::chrono::duration<double> durStringView= std::chrono::steady_clock::now() - start;
std::cout << "std::string_view::substr: " << durStringView.count() << " seconds" << std::endl;
std::cout << std::endl;
std::cout << "durString.count()/durStringView.count(): " << durString.count()/durStringView.count() << std::endl;
std::cout << std::endl;
}
|
数値を提示する前に、私のパフォーマンス テストについて一言言わせてください。パフォーマンス テストの重要なアイデアは、大きなファイルを std::string として読み込み、std::string と std::string_view で多くの部分文字列を作成することです。この部分文字列の作成にどれくらいの時間がかかるのか、私はまったく興味があります.
長いファイルとして「グリム童話」を使用しました。他に何を使用すればよいですか?文字列 grimmTales (24 行目) には、ファイルの内容が含まれています。 37 行目の std::vector
これが数字です。ファイルの長さ、std::string::substr と std::string_view::substr の数値、および両方の比率が表示されます。コンパイラとして GCC 6.3.0 を使用しました。
サイズ 30
好奇心だけで。最適化されていない数値。
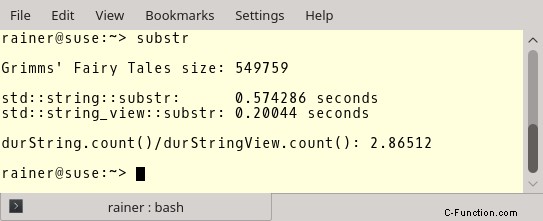
しかし今、より重要な数字に移ります。完全に最適化された GCC。
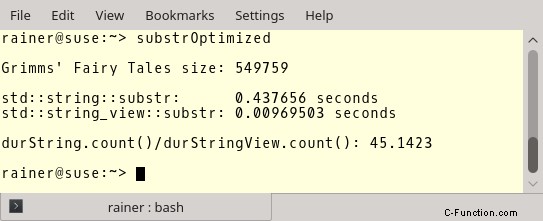
最適化は、std::string の場合には大きな違いはありませんが、std::string_view の場合には大きな違いがあります。 std::string_view で部分文字列を作成すると、std::string を使用するよりも約 45 倍速くなります。それが std::string_view を使用する理由ではない場合は?
さまざまなサイズ
今、私はますます好奇心をそそられています。部分文字列のサイズ カウントを操作するとどうなりますか?もちろん、すべての数値は最大限に最適化されています。小数点第 3 位を四捨五入しました。
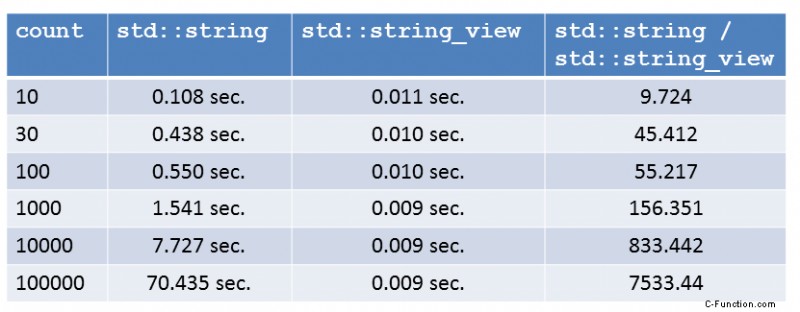
私は驚いていません.数値は、std::string::substr と std::string_view::substr の複雑さの保証を反映しています。最初の複雑さは、部分文字列のサイズに線形に依存します。 2 番目は部分文字列のサイズに依存しません。最終的に、std::string_view は std::string よりも大幅に優れています。
次は?
std::any、std::optional、および std::variant については、さらに記述する必要があります。次の投稿をお待ちください。