std::vector の合計を 3 つの異なる方法で計算した後、結論を導き出します。
3 つの戦略
まずは全数値を概観。 1 つ目は、シングル スレッドのバリアントです。 2 つ目は、合計変数を共有する複数のスレッドです。最後に、同期が最小限の複数のスレッドです。最後の変種であることに驚いたことを認めざるを得ません.
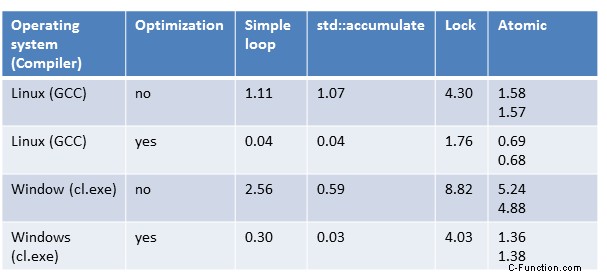
シングル スレッド (1)
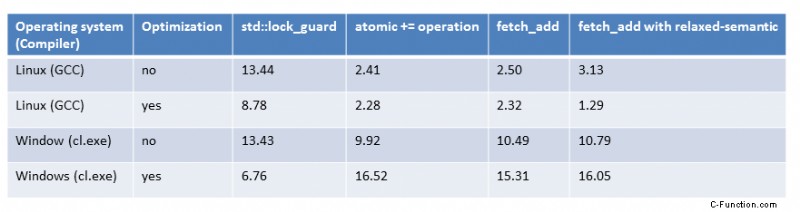
共有合計変数を持つ複数のスレッド (2)
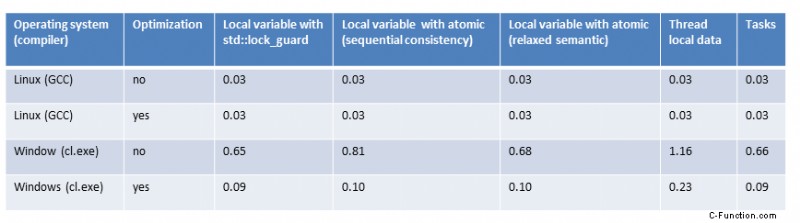
最小同期の複数スレッド (3)
私の観察
簡単にするために、Linux についてのみ説明します。より深い洞察を与えてくれた Andreas Schäfer (https://plus.google.com/u/0/+AndreasSch%C3%A4fer_gentryx) に感謝します。
シングル スレッド
範囲ベースの for ループと STL アルゴリズム std::accumulate は同じリーグにあります。この観察は、最大に最適化されたプログラムと最適化されていないプログラムに当てはまります。最大に最適化されたバージョンが、最適化されていないバージョンよりも約 30 倍高速であることは非常に興味深いことです。最適化されたバージョンのベクトル化された命令 (SSE または AVX) の場合、コンパイラーは合計に使用します。したがって、ループ カウンターは 2 (SSE) または 4 (AVC) 増加します。
共有合計変数を持つ複数のスレッド
共有変数 (2) へのアクセスごとの同期 ポイントを示しています:同期は高価です。私はリラックスしたセマンティックでシーケンシャルな一貫性を破っていますが、プログラムはペンダントよりも約 40 倍遅い (1) または (3)。 パフォーマンス上の理由だけでなく、共有変数の同期を最小限に抑えることが私たちの目標でなければなりません。
最小同期の複数スレッド
最小限の同期スレッド (4 つのアトミック操作またはロック) による合計 (3) 範囲ベースの for ループまたは std::accumulate (1) ほど高速ではありません。 .これは、4 つのコアで 4 つのスレッドが独立して動作できるマルチスレッドのバリアントにも当てはまります。ほぼ 4 倍の改善を期待していたので、これには驚きました。しかし、さらに驚いたのは、私の 4 つのコアが十分に活用されていなかったことです。
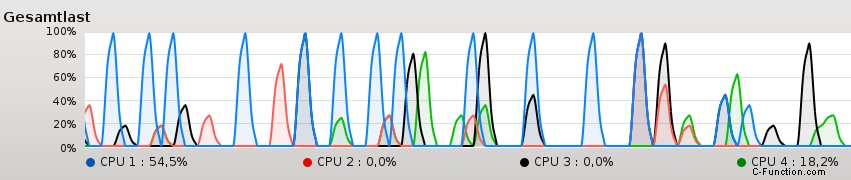
理由は簡単です。コアがメモリから十分な速度でデータを取得できません。あるいは逆に言えば。メモリはコアを遅くします。
私の結論
パフォーマンス測定からの私の結論は、そのような単純な操作 std::accumulate に使用することです。それには 2 つの理由があります。まず、パフォーマンスの向上 バリアントの (3) 費用を正当化しない;次に、C++ には C++17 の std::accumulate の並列バージョンがあります。したがって、シーケンシャル バージョンからパラレル バージョンへの切り替えは非常に簡単です。
次は?
time ライブラリはマルチスレッド ライブラリには属していませんが、C++ のマルチスレッド機能の重要なコンポーネントです。たとえば、ロックの絶対時間を待機するか、スレッドを相対的な時間スリープ状態にする必要があります。次の投稿では、時間について書きます。
.