私の目標は、要約すると、ベクトルのすべての要素です。前回の投稿では単一のスレッドを使用しました。この投稿では、複数のスレッドを使用しているため、PC の能力をフルに活用しています。追加は共有変数で行われます。一見良いアイデアのように見えるものは、非常に単純な戦略です。合計変数の同期オーバーヘッドは、4 つまたは 2 つのコアのパフォーマンス上の利点よりも高くなります。
戦略
前回の投稿に従って、1 から 10 までの 1 億個の乱数を合計します。計算が正しいことを確認するために、ランダム性を減らします。したがって、シードを使用せず、2 つのアーキテクチャで毎回同じ乱数を取得します。したがって、私の合計結果を確認するのは簡単です。両方の計算は、4 CPU の Linux と 2 CPU の Windows PC で実行されます。これまでと同様に、最適化なしで最大化します。 Windows では、私は非常に困惑しました。
興味深い質問は何ですか?
<オール>std::lock_guard による共有変数の保護
共有変数を保護する最も簡単な方法は、mutex をロックでラップすることです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | // synchronizationWithLock.cpp
#include <chrono>
#include <iostream>
#include <mutex>
#include <random>
#include <thread>
#include <utility>
#include <vector>
constexpr long long size= 100000000;
constexpr long long firBound= 25000000;
constexpr long long secBound= 50000000;
constexpr long long thiBound= 75000000;
constexpr long long fouBound= 100000000;
std::mutex myMutex;
void sumUp(unsigned long long& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){
for (auto it= beg; it < end; ++it){
std::lock_guard<std::mutex> myLock(myMutex);
sum+= val[it];
}
}
int main(){
std::cout << std::endl;
std::vector<int> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_int_distribution<> uniformDist(1,10);
for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine));
unsigned long long sum= 0;
auto start = std::chrono::system_clock::now();
std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound);
std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound);
std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound);
std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound);
t1.join();
t2.join();
t3.join();
t4.join();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "Time for addition " << dur.count() << " seconds" << std::endl;
std::cout << "Result: " << sum << std::endl;
std::cout << std::endl;
}
|
プログラムは簡単に説明できます。関数 sumUp (行 20 ~ 25) は作業パッケージで、各スレッドが実行する必要があります。この作業パッケージは、合計変数 sum と std::vector val で構成され、どちらも参照によって取得されます。 beg と end は、合計が行われる範囲を制限します。既に述べたように、共有変数を保護するために std::lock_guard (22 行目) を使用します。各スレッド ライン 41 ~ 44 は、作業の 4 分の 1 を行います。
これがプログラムの番号です。
最適化なし
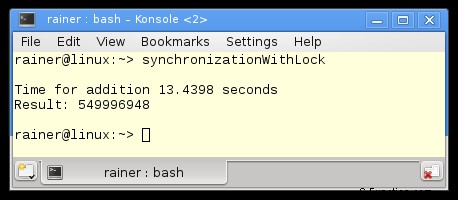
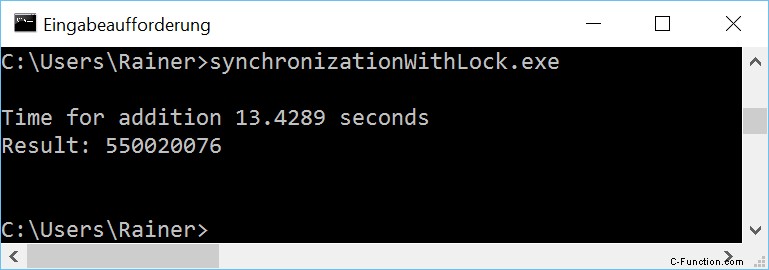
最大限の最適化
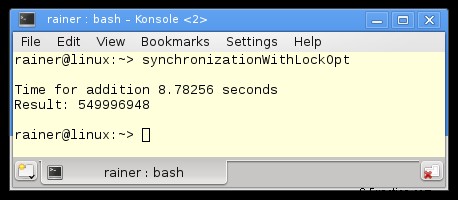
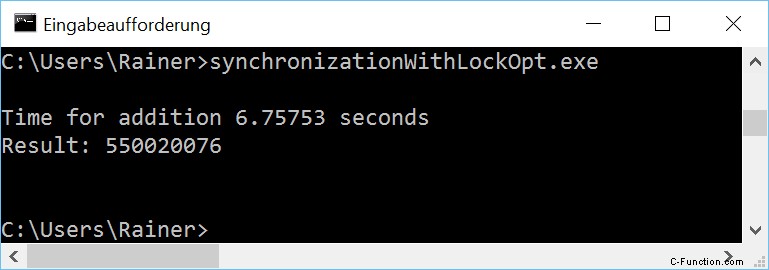
プログラムのボトルネックは、std::lock_guard によって保護された高価な共有変数です。したがって、明白な解決策は、重いロックを軽量のアトミックに置き換えることです。
atomic による加算
変数 sum はアトミックです。したがって、関数 sumUp の std::lock_guard をスキップできます (18 ~ 22 行目)。以上です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | // synchronizationWithAtomic.cpp
#include <atomic>
#include <chrono>
#include <iostream>
#include <random>
#include <thread>
#include <utility>
#include <vector>
constexpr long long size= 100000000;
constexpr long long firBound= 25000000;
constexpr long long secBound= 50000000;
constexpr long long thiBound= 75000000;
constexpr long long fouBound= 100000000;
void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){
for (auto it= beg; it < end; ++it){
sum+= val[it];
}
}
int main(){
std::cout << std::endl;
std::vector<int> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_int_distribution<> uniformDist(1,10);
for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine));
std::atomic<unsigned long long> sum(0);
auto start = std::chrono::system_clock::now();
std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound);
std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound);
std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound);
std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound);
t1.join();
t2.join();
t3.join();
t4.join();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "Time for addition " << dur.count() << " seconds" << std::endl;
std::cout << "Result: " << sum << std::endl;
std::cout << std::endl;
}
|
最適化なし
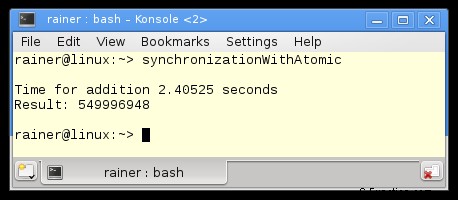
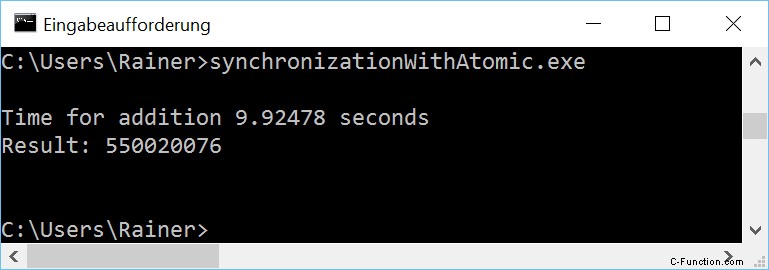
最大限の最適化
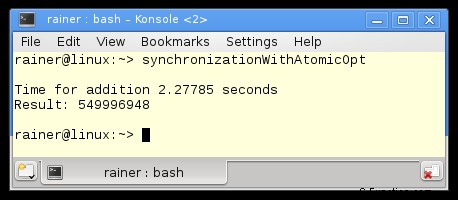
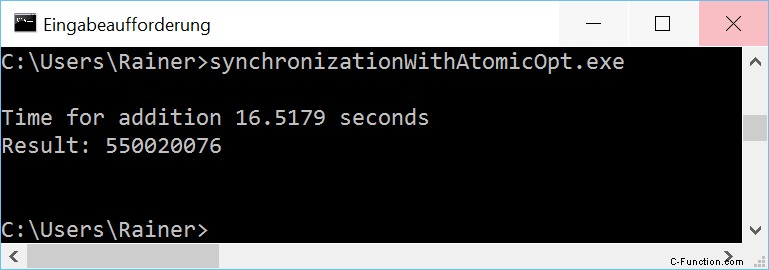
奇妙な現象
数値を注意深く調べると、Windows での奇妙な現象に気付くでしょう。最大に最適化されたプログラムは、最適化されていないプログラムよりも遅くなります。その観察は、次の 2 つのバリエーションにも当てはまります。これは私を困惑させました。コアが 1 つだけの仮想化された Windows 8 PC に加えて、プログラムを実行しました。ここでは、最適化されたバージョンの方が高速でした。 Windows 10 PC とアトミックで奇妙なことが起こっています。
+=以外にも、fetch_add を使用してアトミックの合計を計算する方法があります。試してみましょう。数字は似ているはずです。
fetch_add による加算
ソースコードの変更は最小限です。 20 行目に触れるだけです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | // synchronizationWithFetchAdd.cpp
#include <atomic>
#include <chrono>
#include <iostream>
#include <random>
#include <thread>
#include <utility>
#include <vector>
constexpr long long size= 100000000;
constexpr long long firBound= 25000000;
constexpr long long secBound= 50000000;
constexpr long long thiBound= 75000000;
constexpr long long fouBound= 100000000;
void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){
for (auto it= beg; it < end; ++it){
sum.fetch_add(val[it]);
}
}
int main(){
std::cout << std::endl;
std::vector<int> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_int_distribution<> uniformDist(1,10);
for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine));
std::atomic<unsigned long long> sum(0);
auto start = std::chrono::system_clock::now();
std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound);
std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound);
std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound);
std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound);
t1.join();
t2.join();
t3.join();
t4.join();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "Time for addition " << dur.count() << " seconds" << std::endl;
std::cout << "Result: " << sum << std::endl;
std::cout << std::endl;
}
|
最適化なし
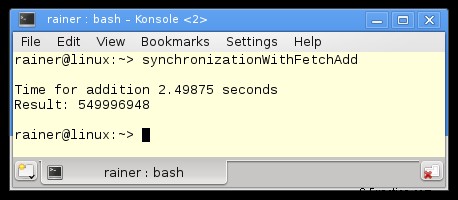
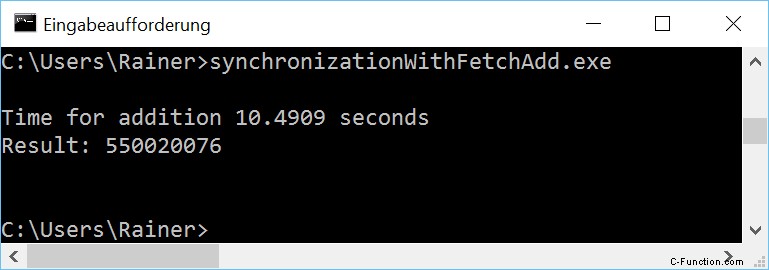
最大限の最適化
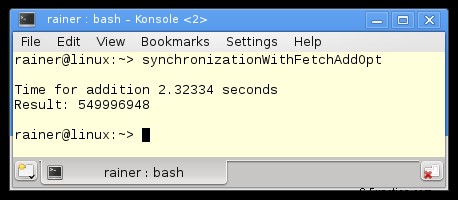
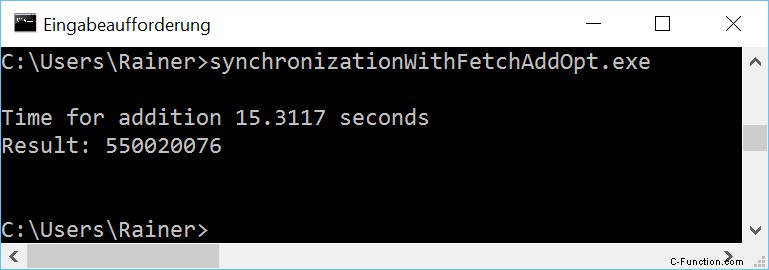
厳密に言えば、fetch_add バリエーションは +=バリエーションの改善ではなく、その逆です。 +=バリエーションはより直感的です。しかし、ちょっとした違いがあります。
fetch_add と緩やかなセマンティックに加えて
アトミックのデフォルトの動作は順次整合性です。このステートメントは、アトミックの追加と割り当て、そしてもちろん fetch_add バリアントに当てはまります。しかし、もっとうまくやることができます。フェッチのバリエーションでメモリ モデルを調整しましょう。これが最適化の最終ステップです。 20 行目にあります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | // synchronizationWithFetchAddRelaxed.cpp
#include <atomic>
#include <chrono>
#include <iostream>
#include <random>
#include <thread>
#include <utility>
#include <vector>
constexpr long long size= 100000000;
constexpr long long firBound= 25000000;
constexpr long long secBound= 50000000;
constexpr long long thiBound= 75000000;
constexpr long long fouBound= 100000000;
void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){
for (auto it= beg; it < end; ++it){
sum.fetch_add(val[it],std::memory_order_relaxed);
}
}
int main(){
std::cout << std::endl;
std::vector<int> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_int_distribution<> uniformDist(1,10);
for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine));
std::atomic<unsigned long long> sum(0);
auto start = std::chrono::system_clock::now();
std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound);
std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound);
std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound);
std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound);
t1.join();
t2.join();
t3.join();
t4.join();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "Time for addition " << dur.count() << " seconds" << std::endl;
std::cout << "Result: " << sum << std::endl;
std::cout << std::endl;
}
|
質問は。 20行目でリラックスセマンティックを使用してもよいのはなぜですか?リラックスしたセマンティックは、あるスレッドが別のスレッドの操作を同じ順序で見ることを保証しません。しかし、これは必要ありません。必要なのは、各追加がアトミックに実行されることだけです。
最適化は効果がありますか?
最適化なし
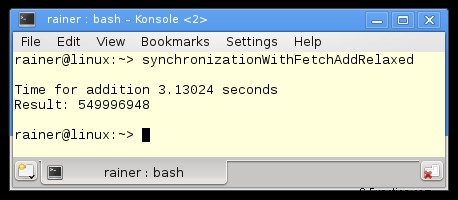
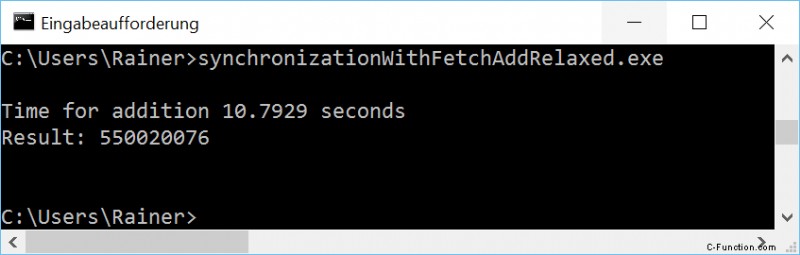
最大限の最適化
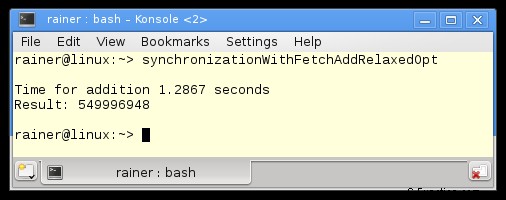
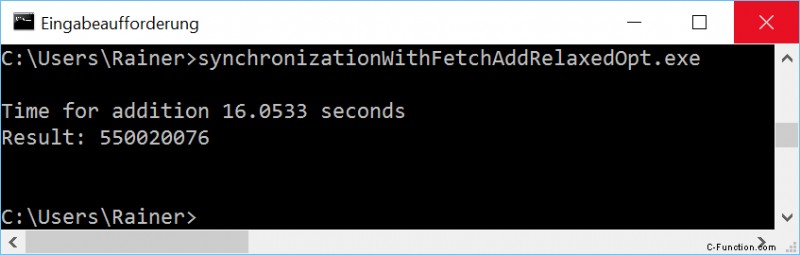
予想どおり、Linux と GCC の場合は、relaxed-semantic が最速の fetch_add バリアントです。 Windows についてはまだ戸惑っています。
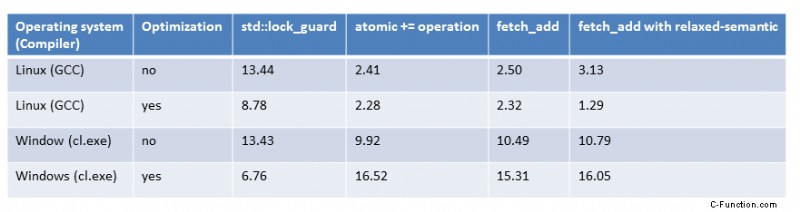
最後に、すべての数字を表にまとめます。
概要
共有変数へのアクセスを連続的に最適化し、それに応じてパフォーマンスを改善しましたが、結果はあまり有望ではありません。 std::accumulate を使用したシングルスレッドの場合の追加は、はるかに高速です。正確に言うと40回。
次は?
次の投稿で、2 つの世界の中で最も優れたものを組み合わせます。 1 つのスレッドでの非同期加算と、多数のスレッドの能力を組み合わせます。 std::accumulate のシングル スレッド バリアントのパフォーマンスを上回るかどうか見てみましょう。